Immagini Jpeg - jpg
Immagini Jpeg - jpg
Questo sito utilizza cookie, anche di terze parti. Se vuoi saperne di più leggi la nostra Cookie Policy. Scorrendo questa pagina o cliccando qualunque suo elemento acconsenti all’uso dei cookie.I testi seguenti sono di proprietà dei rispettivi autori che ringraziamo per l'opportunità che ci danno di far conoscere gratuitamente a studenti , docenti e agli utenti del web i loro testi per sole finalità illustrative didattiche e scientifiche.
Le informazioni di medicina e salute contenute nel sito sono di natura generale ed a scopo puramente divulgativo e per questo motivo non possono sostituire in alcun caso il consiglio di un medico (ovvero un soggetto abilitato legalmente alla professione).
Immagini Jpeg - jpg
Capitolo 1
Introduzione a JPEG
JPEG è l’ acronimo per “Joint Photographic Experts Group”. Questa organizzazione ha creato JPEG standard per la compressione di immagini. JPEG standard risulta essere abbastanza complesso perché esso definisce oltre ad un formato specifico per le immagini anche un numero di tecniche specifiche per la compressione.
Tutti i metodi di compressione usati sono di tipo “lossy”; questo tipo di codifica permette di creare un compromesso tra l’accuratezza dell’immagine rigenerata e la potenza di compressione. Permette di generare un’immagine di dimensioni anche 30 volte più piccole dell’originale. Si può capire il loro dominante uso nelle applicazioni grafiche.
1.1 Tipi di compressione
Lo standard JPEG definisce quattro tipi di compressione: gerarchica, progressiva, sequenziale e lossless e per ognuno detta i passi da seguire per effettuare la codifica:
Gerarchica: è un metodo progressivo nel quale l’immagine è divisa in un numero di sotto immagini chiamate frame. Un frame è una collezione di una o più scansioni di un immagine. Il primo frame crea una versione dell’immagine a bassa risoluzione, i successivi definiscono l’immagine con un sempre più maggior risoluzione.
Progressiva: le diversi componenti dell’immagine sono decodificate in scansioni multiple. La scansione iniziale crea una rozza versione dell’immagine mentre le successive la ridefiniscono. La successione di immagini creata nella decodifica viene vista anche nel momento in cui si carica il file immagine. Può essere utile questo metodo in un ambiente network dove il canale di comunicazione dei dati è lento e quindi la prima immagine che appare è quella di minor dimensione. E’ poco usato.
Sequenziale: l’immagine è codificata dall’alto verso il basso, supporta un campionamento con 8 o 12 bit di precisione. Ogni componente colore è completamente codificato in una singola scansione. In molti formati l’intero processo di compressione è memorizzato in una zona contigua del file. In questa modalità due tipi di processi di codifica sono definiti dallo standard JPEG: codifica Huffman e codifica aritmetica. Nella maggior parte del suo utilizzo JPEG viene usato con la codifica di Huffman e dati campione di 8-bit. E’ il piu usato.
Lossless: permette di preservare l’esatta immagine originale.
1.2 Codifica-decodifica
Questo standard di compressione definisce in maniera molto semplice molti percorsi per arrivare allo stesso obbiettivo. E’ quindi molto complicato realizzare un decodificatore in grado di interpretare tutti i vari tipi di codifica.
Viene lasciata molta libertà nel momento della decodifica; lo standard non definisce l’ordine delle operazioni da fare per visualizzare un’immagine, in modo da assecondare le esigenze dell’applicazione in uso.
1.3 Frequenza di campionamento
A differenza di un’immagine sul monitor di un computer, una fotografia possiede una variazione continua dei colori. Per convertire la fotografia in una immagine digitale, bisogna scandire l’immagine e misurare i valori che la compongono in intervalli regolari.
Nella maggior parte dei formati immagini esistenti tutte le componenti colore sono campionate alla stessa frequenza, in JPEG è possibile variarle secondo il proprio utilizzo specifico. Le frequenze di campionamento permettono all’immagine di essere compressa variando la quantità di informazione che contribuisce da ogni componente, quindi cercando di minimizzare l’informazione da memorizzare.
Quando si opera con JPEG ad ogni componente da campionare è assegnata una frequenza di campionamento orizzontale e verticale che può assumere un valore da 1 a 4. Più alto è il valore maggiore è la quantità di dati utilizzata da ogni componente.
Il processo di riduzione dei contributi di una componente è chiamato sotto campionamento. Il processo inverso è chiamato sovra campionamento.
1.4 Scansione Interleaved e Non-Interleaved
Una scansione dell’immagine può contenere dati per una o più componenti (ad es. immagini con spazio colore YCbCr). Se la scansione possiede una sola componente viene denominata Non-interleaved, e i dati vengono, in questo caso, codificati una riga alla volta dall’alto verso il basso da sinistra a destra.
Se la scansione possiede più di una componente allora è conosciuta come Interleaved. In questo caso la codifica avviene in gruppi di dati che prendono il nome di MCU (Minimun Coded Units). La frequenza di campionamento verticale specifica il numero di unità lungo le righe che contribuisce ad una MCU, e la frequenza verticale definisce il numero di unità lungo le colonne (nel caso non-interleaved è sempre a 1 unita).
Nella figura seguente mostra dati che devono essere codificati in una MCU di un’immagine a tre componenti con una frequenza di campionamento di 4x2, 2x4, 1x1.

Figura 1
L’unita più piccola rappresentata sono i pixel, i rettangoli numerati sono i gruppi di pixel campionati e i numeri rappresentano l’ordine di codifica nella MCU. Le dimensioni di una immagine devono sempre essere un multiplo della dimensione di una MCU, se mancano dei pixel essi sono inseriti copiando l’ultima riga o colonna dell’immagine.
Capitolo 2
Formato del file JPEG
Diamo ora uno sguardo alla struttura del file JPEG, spiegando con quale metodo vengono memorizzate le varie parti dell’immagine.
2.1 Marker
Sono usati per segnalare che tipo di dati è inserito nel file. Essi sono di una lunghezza di 2bytes, con il primo byte che ha sempre il valore FF16. Il secondo byte contiene invece il codice specifico del tipo di marker.
I marker si possono raggruppare in due tipi: Stand-alone che non contengono dati oltre i due byte del marker stesso; quelli che non rientrano in questa categoria sono immediatamente seguiti da un valore di due byte che segnala il numero di byte di dati che il marker contiene.
I dati compressi sono l’unica parte che nel file non occorre essere messa tra i marker; sono sempre seguiti immediatamente dal marker SOS, all’interno possono trovarsi solo i marker RSTn.
La compressione raramente produce il valore FF16, nel caso venisse prodotto esso è codificato in due byte, il primo FF16 seguito da 0016.
2.2 Descrizione dei Marker
Le restrizioni principali sono:
- solo i marker RST e DNL possono comparire nella parte di dati compressi
- il file deve partire con il marker SOI seguito da APP0.
- L’ultimo marker nel file deve essere EOI, messo subito dopo la parte di dati compressi.
I principali marker usati sono:
APPn: i marker AP0 – APP15 sono usati dall’applicazione che elabora l’immagine per conservare ulteriori informazioni riguardo l’immagine trattata.
COM: delimita la stringa per i commenti, come ad esempio il copyright.
DHT: (Define Huffman Table) definisce (o ridefinisce) le tabelle di Huffman, le quali sono identificate dalla classe (DC o AC) e da un numero.
DRI: (Define Restart Interval) questo marker può essere usato quando il decodificatore interrompe la scansione, esso infatti può usare il DRI marker per riprendere la decodifica dal punto definito.
DQT: (Define Quantization Table) definisce (o ridefinisce) le tabelle di quantizzazione usate nell’immagine.
EOI: (End of image) delimita la fine del file JPEG
RSTn: sono usati per delimitare blocchi di dati indipendentemente dalla codifica di compressione.
SOI: (Start Of Image) stabilisce l’inizio del file JPEG.
SOFn: (Start Of Frame) stabilisce l’inizio di un frame.
SOS: (Start Of Scan) delimita l’inizio dei dati compressi per una scansione nel JPEG strema.
2.3 Formato JFIF
E’ l’acronimo di “JPEG file format”; esso definisce:
- una stringa per identificare il file JPEG
- spazio colori utilizzato
- densità dei pixel dell’immagine
- thumbnails
- la relazione che intercorre tra i pixel e la frequenza di campionamento
Come spazio colori specifica di usare YCbCr.
Lo standard JPEG originale non definisce un particolare formato del file, ma la comunità ha assunto come universale JFIF.
Capitolo 3
Operazioni per la compressione
Quali sono i passi per creare un file in formato JPEG ? Vediamo adesso una breve descrizione dei passi da seguire per la compressione a partire dall’immagine digitalizzata che ci proviene da qualsiasi dispositivo tipo scanner, fotocamera ecc….

Figura 2
3.1 (T) Trasformazione delle componenti discrete coseno (DCT)
Lo scopo è quello di arrivare ad una rappresentazione più adatta ad essere compressa.
Primo passo è convertire lo spazio colori RGB in quello YCbCr.
Si effettua poi il sotto-campionamento, questo procedimento è opzionale, non sempre viene effettuato. Le immagini vengono poi compresse in blocchi da 8x8 pixel e la DCT converte il valore dei pixel di ogni blocco in una somma di funzioni coseno.
3.2 (Q) Quantizzazione
Lo scopo è quello di ricercare quale è l’effettiva informazione, e quali dati possono essere trascurati senza che la nostra percezione visiva riesca a valutare sostanziali differenze.
Si eliminano le componenti della DCT che non sono essenziali per la ricreazione dell’immagine originale.
3.3 (C) Codifica di Huffman
Lo scopo è quello di trovare un modo alternativo di rappresentare i simboli da memorizzare su file.
Codifica i coefficienti della DCT quantizzata e introduce una rappresentazione differente dei blocchi di dati.
Capitolo 4
Trasformazioni
Vediamo adesso di chiarire quali sono le trasformazioni che bisogna effettuare sull’immagine digitalizzate per effettuare la compressione della stessa. L’ordine con cui verranno descritte le operazioni è l’esatta sequenza in cui vengono generalmente eseguite.
4.1 Cambio di spazio Colore
La conversione tra lo spazio RGB e YCbCr è definita dalle seguenti formule:
Da RGB a YCbCr:
Equazione 1

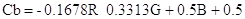
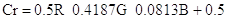
Da YCbCr a RGB:
Equazione 2



Il valore Y è chiamato luminanza. Questo valore è usato nei monitor monocromatici per rappresentare un colore RGB.
Fisiologicamente esso rappresenta l’intensità di un colore RGB percepito dal nostro occhio. Come si può vedere la Y è ricavata dando degli opportuni pesi alle componenti RGB del colore; infatti l’occhio umano è molto più sensibile al verde seguito dal rosso e per ultimo il blu.
Invece i valori Cb e Cr sono chiamati valori di crominanza e rappresentano le due coordinate in un sistema che misura la sfumatura e la saturazione del colore (indicativamente questi due valori stabiliscono quanto blu e quanto rosso è il colore).
4.2 Sotto-campionamento
Lo standard JPEG prende per certo che l’occhio umano è molto più sensibile alla luminanza di un colore che alle componenti di crominanza. Quindi la luminanza è presa per ogni pixel mentre i valori di crominanza sono presi come valor medio di un blocco 2x2 pixel. Non è necessario che la crominanza sia presa come valor medio ma i risultati pratici hanno dimostrato che questa via è un ottimo compromesso tra la compressione e percezione visiva della nuova immagine campionata.
JPEG inoltre stabilisce che per ogni componente colore devono essere definiti due coefficienti di campionamento: uno orizzontale e uno verticale.
I metodi più usati sono 4:2:2 o 4:2:1 (Y:Cb:Cr), questa notazione significa che per insiemi di quattro pixel io campiono 4 volte per la componente Y, 2 volte per la componente Cb e 2 o 1 volta per la componente Cr.
4.3 Suddivisione 8x8
L’immagine viene divisa in blocchi di 8x8 pixel, ed a ognuno viene applicata la trasformata DCT (verrà spiegata nel prossimo paragrafo). Se le dimensioni lungo la coordinata X (larghezza) dell’immagine non sono suddivisibili per 8, il codificatore le rende divisibili completando la parte mancante aggiungendo con le colonne che stanno più a destra dell’immagine originale. Lo stesso avviene se è il caso della coordinata Y (altezza) a non essere divisibile per 8, il decodificatore completa le rimanenti linee aggiungendo le ultime righe dell’immagine originale.
I blocchi vengono creati da sinistra a destra dall’alto verso il basso. Se un pixel nel blocco 8x8 ha le tre componenti (Y,Cb,Cr) la DCT deve essere applicata separatamente ai tre blocchi 8x8 rappresentativi di ogni componente colore.
Si usa la notazione che il primo blocco contiene i valori della luminanza, gli altri due invece quelli della crominanza, rispettivamente i valori Cb e Cr.
4.4 DCT
La Trasformata dei Coseni Discreta (DCT) è il cuore della compressione JPEG. Il valore in ingresso della DCT è un certo insieme e l’output è un altro insieme della stessa dimensione. La DCT è una trasformazione invertibile, questo significa che l’output dei coefficienti che troviamo possono essere riutilizzati per ricreare i dati originali.
La DCT trasforma l’insieme dei valori di input in un insieme di coefficienti coseno incrementandone la frequenza. Quindi i valori originali sono trasformati in una somma di funzioni coseno. Essa è usata sia in una che in due dimensioni. Il numero dei valori in input è una potenza di due. In JPEG DCT e IDCT (inverse DCT) sono sempre in due dimensioni per blocchi di dati 8x8.
Per capirne il funzionamento introduciamo prima la DCT in una dimensione.
4.4.1 DCT in una dimensione
Consideriamo un array V di dimensione N e un array T della stessa dimensione.
Equazione 3

dove
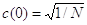
Invece la IDCT uni dimensionale usata per il processo inverso è:
Equazione 4

questa è una somma di funzioni coseno di sempre più elevata frequenza dove i coefficienti della DCT sono l’ampiezza di ogni funzione coseno nella sommatoria.
In JPEG i valori campionati sono rappresentati usando 8 bit quindi i valori rientrano in un range tra i valori 0 e 255. JPEG richiede che venga sottratto il valore 128 da ogni valore di input in modo che tutti i valori stiano nel range tra –128 e 127 prima del calcolo della DCT. Questo ha un effetto di riduzione della grandezza dei primi coefficienti della DCT, ma non ha alcun effetto sugli altri. Di conseguenza dopo aver applicato la IDCT i valori devono essere riportati al corretto range aggiungendo ad ognuno il valore 128.
Se la DCT e la IDCT sono applicate in sequenza usando nei calcoli una infinita precisione otteniamo sempre esattamente lo stesso insieme di valori dati in input.
Sfortunatamente i computer non lavorano con infinita precisione; in JPEG poi durante la compressione tutti i valori della DCT sono approssimanti ad interi, questo significa introdurre un errore quando si comprime e decomprime un’immagine. L’errore è piccolo ma esiste sempre.
Il primo coefficiente della DCT è conosciuto come coefficiente DC, gli altri invece vengono tutti nominati con coefficienti AC. Questi due tipi in JPEG vengono codificati in maniera diversa.
Vediamo questo esempio:
Tabella 1

Adesso vediamo come si comporta la IDCT per i corrispondenti valori della DCT:
|
|
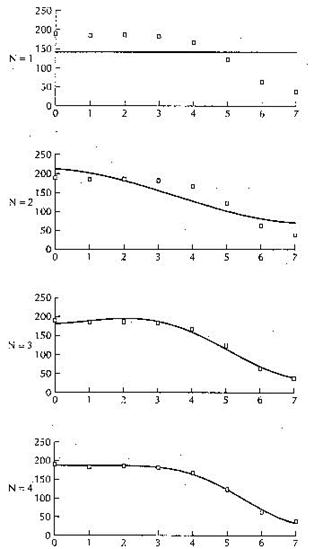

Figura 3
Possiamo notare che se ci spostiamo dal primo grafico all’ultimo le nostri funzioni si avvicinano sempre più al dato originale. Nei primi grafici il cambiamento è molto netto, ma negli ultimi è molto piccola la differenza. Questo fenomeno è la chiave della compressione in JPEG, le componenti più elevate della DCT sono quelle che contribuisco meno alla formazione del segnale originale, quindi possono essere scartate producendo una immagine molto simile all’originale.
Questo procedimento permette sempre di avere ottimi risultati? Per quanto riguarda le immagini fotografiche la risposta è affermativa, la cosa è da rivedere per immagini dove occorrono frequentemente cambiamenti bruschi (ad esempio un disegno tecnico), qui i formati per la memorizzazione consigliati sono diversi e di miglior risultato come PNG.
4.4.2 DCT in due dimensioni
Adesso vediamo come si sviluppa la trasformata coseno in due dimensioni; consideriamo che in JPEG prendiamo blocchi di 8x8 pixel, i quali devono essere trasformati dalla DCT:
Equazione 5

dove:

 , con i o j = 0
, con i o j = 0
La IDCT invece assume la forma:
Equazione 6

Il valore di N è sempre 8.
L’uso delle equazioni bidimensionali, fa sorgere delle complicazioni nei calcoli, facilmente risolvibili con le operazioni tra matrici e vettori. Quindi avremo:
T = MVMT
e la IDCT:
V =MTTM
Dove V è una matrice 8x8 e M è la matrice seguente:
Equazione 7

Capitolo 5
Quantizzazione
Noi sappiamo che nella DCT uni-dimensionale non abbiamo bisogno di tutti i coefficienti della IDCT per ricostruire i dati originali con buona approssimazione. Vi sono però delle situazioni in cui dobbiamo usare molti se non tutti i coefficienti per avere un buon risultato. Lo stesso discorso vale per la DCT bi-dimensionale. Quindi dopo aver calcolato la DCT il passo successivo è quello di trovare e scartare i coefficienti che non contribuiscono in maniera decisiva alla ricostruzione dell’immagine.
Questo processo è la chiave della compressione JPEG. L’idea è quella di rimuovere le alte frequenze presenti nell’immagine originale. Questo si può fare perché l’occhio umano è molto più sensibile alle variazioni di basse frequenze che a quelle alte. Le perdite sono piccolissime e pressoché impercettibili all’occhio umano.
Un altro fatto importante è che nella maggior parte delle immagini la variazione di colore tra pixel vicini è molto piccola, questo significa che l’immagine ha una bassa quantità di dettagli, quindi l’informazione importante sarà tutta contenuta nelle frequenze più basse.
5.1 Tabelle di quantizzazione
Lo standard JPEG definisce un semplice meccanismo, chiamato quantizzazione. Per quantizzare l’immagine è sufficiente dividere il campione per un altro valore e arrotondare questo al più vicino intero.
Equazione 8
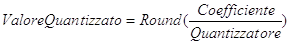
Il processo inverso
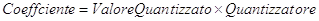
Il valore “quantizzatore” è definito nelle tabelle di quantizzazione:

Figura 4
Ogni valore delle tabelle è usato per quantizzare il corrispondente coefficiente della DCT. Lo standard JPEG non specifica i valori da usare nelle tabelle, queste dovrebbero essere generate per ogni immagine. Pero il processo risulterebbe oneroso e quindi le tabelle che vi sono in figura sono un ottimo risultato trovato empiricamente.
Il risultato della quantizzazione è una serie di valori del tipo (in figura sono esposti i risultati dopo la trasformazione rispetto alla componente Y del colore):

Figura 5
Si nota subito l’elevato numero di zeri prodotto in corrispondenza dei coefficienti AC.
Capitolo 6

Codifica
6.1 Ordinamento DCT
Dopo aver costruito i valori quantizzati per i coefficienti della DCT, adesso JPEG effettua il loro ordinamento in modo da avere il maggior numero di zeri consecutivi in un ordinamento sequenziale di valori. L’ordinamento segue un percorso a zig-zag come in figura.

Figura 6
6.2 RLC (Run Lenght Coding)
I coefficienti ordinati li dividiamo nelle due categorie DC e AC, nella prima rientra sempre un solo valore che è sempre il primo in alto a sinistra, gli altri sono tutti coefficienti AC.
Se prendiamo l’esempio prima sviluppato (Figura 5) troviamo che i coefficienti sono:
DC: -38
AC: 18, -9, -3, -8, 1, -3, 1, -2, 4, -2, 4, 0, 3, -1, 0, 1, 1, 0, -1, -1, 0, 0, 0, -1 (39 zero)
In modo compatto essi vengono ordinati nella forma (n,m):
(0,18), (0,-9), (0,-3), (0,-8), (0,1), (0,-3), (0,1), (0,2), (0,4), (0,-2), (0,4), (1,3), (0,-1), (1,1), (0,1), (1,-1), (3,-1), (0,0)
la struttura di questa notazione (n,m) ha il significato di rendere compatti gli zeri consecutivi che si trovano dopo la quantizzazione; n è il numero di zeri che precede il coefficiente m. Il caso particolare (0,0) significa che da quel punto in poi la matrice è composta di soli zeri. Nel caso vi siano tra due coefficienti più di 15 zeri la notazione deve essere divisa in due parti, ad esempio:
34,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,3,0,0,0,0,2,33x0,89,0,0,0 EOB
codificato in: (0,34), (15,0), (2,3), (4,2), (15,0), (15,0), (1,89), (0,0)
6.3 Codifica del coefficiente DC
Il coefficiente DC nel vettore quantizzato corrisponde alla più bassa frequenza del blocco 8x8 (frequenza 0) e prima della quantizzazione è matematicamente uguale alla somma dei valori del blocco 8x8 diviso per il numero 8 (questo è circa una media dei valori campionanti nel blocco).
JPEG standard stabilisce una stretta relazione tra i coefficienti DC di blocchi consecutivi e quindi è stato deciso di codificarli in maniera diversa dagli altri codificando le differenze tra coefficienti DC di blocchi 8x8 consecutivi.

in modo tale che il blocco in analisi DCi è uguale:

Nella decodifica JPEG si parte dal valore 0, si considera il primo coefficiente DC uguale a zero (DC0 = 0), si aggiunge il valore corrente al valore decodificato dal JPEG (il valore Diff).
6.4 Codifica di Huffman
Nella lingua Inglese vi sono lettere che occorrono più frequentemente di altre. Ad esempio la E e la T sono le più frequenti mentre la X e la Q sono molto meno usate. Questa classificazione dell’ alfabeto è stata utilizzata per scrivere il codice Morse; esso per le lettere più frequenti associa pochi simboli invece per quelli meno usati utilizza più simboli.
Nel mondo dei computer ogni carattere possiede un numero fisso di bit, questo per esecuzioni veloci è molto efficiente, ma per applicazioni come può essere la compressione delle immagine non può essere una soluzione buona; si cerca quindi utilizzare dei codici a lunghezza variabile, e il miglior schema per ottenere questo risultato è la codifica di Huffman.
Il procedimento è semplice, esso giunge alla creazione di un albero binario che contiene simboli dal basso verso l’alto in modo tale che i più usati si trovino vicino alla radice.
Per prima cosa si crea un contenitore di nodi associati ai valori dei simboli con la loro occorrenza. Poi si itera il seguente procedimento fino a giungere ad un albero binario, senza nodi separati:
- individuare nel contenitore i due valori o nodi con la più bassa frequenza e rimuoverli. Se più di un valore ha la stessa bassa frequenza sceglierne uno.
- creare un nuovo albero e mettere i due valori trovati prima in due rami.
- creare la frequenza del nuovo albero facendo la somma delle frequenze dei figli
- aggiungi il nuovo nodo nel contenitore
Alla fine tutti i valori sono ordinati in un albero binario il quale assegna il valore zero ad una parte dei rami e il valori uno all’altra parte.
Si ottiene un codice binario per ogni lettera analizzato, il codice è univoco per ogni simbolo. Questo è molto importante perché senza questo sarebbe impossibile decodificare il codice di Huffman codificato.
Vi è un altro metodo per generare il codice di Huffman esso viene generato a partire dal numero di bit di ogni simbolo. Con questo metodo ad ogni simbolo sono associati due valori, uno il numero dei bit (inizialmente a zero) e l’altro è la frequenza in cui occorre.
- Prendiamo ora i due simboli con minor frequenza, uniamoli in un contenitore comune e ad essi associamo la frequenza somma delle frequenze dei singoli simboli.
- Ogni volta si prendono i simboli o contenitori con minor frequenza e si sommano, inserendoli in nuovo contenitore.
- si itera, fino ad arrivare ad un singolo contenitore dove vi sono tutti i simboli con associati ad ognuno il numero di bit.
Si genera poi il codice usando un semplice algoritmo.
6.5 Codifica Huffman in JPEG
Le tabelle di Huffman sono memorizzate nel marker DHT dove sono memorizzati i codici ordinati in maniera crescente. I valori possibili sono interi da 0 a 255. Diversi codici possono essere creati dallo stesso simbolo; lo standard JPEG non specifica come deve essere esattamente generato il codice di Huffman. Non si richiede neanche che sia ottimale.
Vi sono due restrizioni imposte da JPEG; la prima consiste che nessun codice generato dal procedimento di Huffman abbia tutti i bit a 1. Questo problema si risolve inserendo un valore tampone (che poi scarteremo), il quale alla fine del procedimento di creazione dei codici avrà associato il codice più lungo composto da soli 1, essendo il valore più raro nell’intero testo da codificare. La seconda restrizione riguarda il limite di 16 bit alla lunghezza del codice. La maggior parte delle volte la codifica di Huffman non crea problemi, ma nel caso si verificassero è sufficiente fare delle piccole trasformazioni all’albero creato.
6.6 Decodifica Huffman in JPEG
Quando si legge un file JPEG esso contiene una serie di valori per ogni codice di Huffman e una lista di simboli ordinati. Da queste informazioni noi abbiamo bisogno di inizializzare le tabelle per convertire in codice di Huffman nel corretto ordine sequenziale di input adoperato all’origine. Finche il codice di Huffman varia in lunghezza bisogna leggere i bit uno alla volta. Il nostro primo problema è dire quando abbiamo letto tutto il codice di Huffman.
Un metodo per la decodifica è quello di ricrearsi l’albero contenente i valori trovati in corrispondenza dei loro codici. Partire sempre dalla radice dell’albero e controllare bit per bit il percorso dello stream che si sta analizzando.
Capitolo 7
JPEG Sequenziale: Decodifica
Vediamo ora quali passi deve eseguire il decodificatore per visualizzare l’immagine codificata nella standard JPEG sequenziale.
7.1 Dimensioni delle MCU
Lo standard JPEG compresso consiste in una sequenza di MCU codificate e ordinate. Il primo passo è quello di determinare il numero di unita dati (di solito blocchi 8x8) che compone ogni MCU e il numero di MCU che sono state usate per codificare l’immagine.
Per ogni componente della scansione, il numero di pixel è:
Equazione 9


dove
Fx = frequenza orizzontale di campionamento di una componente
Fxmax = massima frequenza orizzontale di campionamento delle componenti
Fy = frequenza verticale di campionamento di una componente
Fymax = massima frequenza verticale di campionamento delle componenti
Se la scansione è di tipi Non-interleaved, ogni MCU consiste di una unita dati. Quindi il numero di MCU nella scansione è dato da MCUsx x MCUsy dove:
Equazione 10


Se la scansione è di tipo interleaved allora
Equazione 11


7.2 Decodifica delle unità dati
Il primo passo dopo aver determinato le dimensioni e il numero delle MCU è quello di creare i coefficienti DC codificati con Huffman. Poi determinare i coefficienti AC codificati usando il metodo RLC e Huffman. I due tipi di coefficienti sono decodificati con tabelle di Huffman diverse.
7.2.1 Coefficienti DC
Questi coefficienti sono memorizzati come differenza tra il valore DC precedentemente codificato e il valore DC corrente. Sono poi codificati in due parti la prima parte è un lunga un byte codificata con Huffman e specifica la grandezza (n) della differenza del coefficiente DC. I codici sono i seguenti:

Figura 7
Per trovare il valore della differenza del valore DC leggo un numero di bit uguale al valore prima decodificato (n), se il valore (n) è zero allora non vi sono bit da leggere.
Il primo bit dopo il valore (n) è il segno della differenza se è a zero significa che la differenza è negativa se è uno allora la differenza è positiva.
7.2.2 Coefficienti AC
La decodifica dei coefficienti AC è un po’ più complicato. Essi sono memorizzati da ogni blocco 8x8 nell’ordine a zigzag. Il decodificatore usa la tabella Huffman per i coefficienti AC per decodificare il valore di un byte. Questo valore è diviso in una coppia di 4 quattro bit. I bit di ordine più basso contengono la grandezza del valore, e i quattro più elevati contengono il numero di zero che precedono nell’ordine il coefficiente.
La tabella che segue mostra i valori possibili di lunghezza dei coefficienti AC, nel loro corrispondente range di valori. Si nota che non c’è il valore zero, questo perché esso è codificato usando il metodo RLC. L’unica differenza tra i coefficienti AC e DC è che per gli AC viene codificata non la differenza ma il valore reale.
Due codici speciali sono usati nella codifica. Uno 0016 è usato per rappresentare che tutti i rimanenti coefficienti sono a zero. L’altro F016 rappresenta che vi sono 16 zero consecutivi.
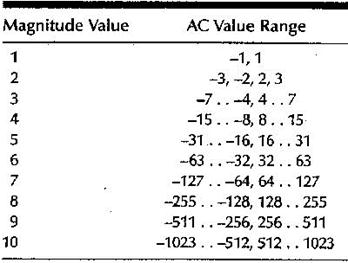
Figura 8
Per ogni unita dati (blocchi 8x8) il processo di decodifica dei coefficienti AC è ripetuto finche tutti i coefficienti sono decodificati. Una unita dati è completa quando occorre un marker di fine blocco oppure quando l’ultimo coefficiente è decodificato.
7.3 Fasi finali della decodifica
Dopo aver letti i coefficienti della DCT dobbiamo applicare la dequantizzazione, semplicemente moltiplicando ogni coefficiente con il corrispondente valore che si trova nella tabella di quantizzazione. Dopo questa fase calcoliamo la IDCT, la quale darà come risultato i valori campionati.
Abbiamo ora i valori sotto-campionati YCbCr. Dobbiamo ora creare l’immagine RGB. Se creiamo una immagine a toni di grigio il processo è finito, infatti dal valore di Y ricaviamo l’informazione di colore che ci serve. Invece per l’immagine a colori la prima cosa da fare è il sovra-campionamento. Dopo questo procedimento noi abbiamo i valori Y, Cb, Cr per ogni pixel. L’ultimo passo è la trasformazione dai due spazi colori.
Bibliografia

titolo : Compressed image file formats : JPEG, PNG, GIF, XBM, BMP / John Miano.
editore : Reading, Mass. : Addison Wesley, 1999
ISBN : 0201604434
Segnatura biblioteca, Dipartimento di Informatica Università Statale di Milano: cd-l_103
titolo : Digital image processing / Rafael C. Gonzalez, Richard E. Woods.
editore : Reading, Mass. : Addison-Wesley, 1992
ISBN : 0201508036
Segnatura biblioteca, Dipartimento di Informatica Università Statale di Milano: graf_191
titolo : Fundamentals of electronic image processing / Arthur R. Weeks, Jr.
editore : Bellingham, Wash., USA : SPIE Optical Engineering Press ;
New York : IEEE Press, 1996
ISBN : 0780334108
Segnatura biblioteca, Dipartimento di Informatica Università Statale di Milano: graf_287
Fonte: http://web.tiscali.it/sliker/jpeg/Jpeg.doc
Sito web: http://web.tiscali.it/sliker/
Autore del testo: M. Ronchetti
Parola chiave google : Immagini Jpeg - jpg tipo file : doc
Immagini Jpeg - jpg
Visita la nostra pagina principale
Immagini Jpeg - jpg
Cosa significa jpeg
Cosa significa jpg
algoritmo di compressione jpeg
Termini d' uso e privacy