File system
File system
Questo sito utilizza cookie, anche di terze parti. Se vuoi saperne di più leggi la nostra Cookie Policy. Scorrendo questa pagina o cliccando qualunque suo elemento acconsenti all’uso dei cookie.I testi seguenti sono di proprietà dei rispettivi autori che ringraziamo per l'opportunità che ci danno di far conoscere gratuitamente a studenti , docenti e agli utenti del web i loro testi per sole finalità illustrative didattiche e scientifiche.
File system
I file system
I processi, ma anche i thread, finora ampiamente discussi nel corso di queste stesse note hanno bisogno di memorizzare e di rintracciare le informazioni a loro utili e/o precedentemente elaborate. Essi, infatti, assolvono ad un importante compito: manipolano l’informazione per conto dell’utente, che impartisce loro dei comandi. La manipolazione dell’informazione avviene esclusivamente nello spazio di indirizzamento concesso in memoria fisica al processo e, in ogni caso, la capacità di memoria non può mai eccedere lo spazio di indirizzamento virtuale, quello cioè disponibile sul disco. Se per alcune applicazioni lo spazio riservato in memoria fisica può rivelarsi sufficiente, per alcune applicazione, invece, esso è addirittura troppo limitato (pensate ad esempio a tutte quelle applicazioni che interagiscono con le basi di dati ed a quanto siano estese queste basi di dati che devono quindi essere memorizzate sulla memoria virtuale e caricate a pezzi sulla memoria fisica). Ed ancora, l’informazione manipolata nella memoria fisica e poi scaricata sulla memoria virtuale deve avere un importante caratteristica, deve essere duratura nei confronti del processo. In altre parole un processo può terminare ma l’informazione da esso prodotta deve essere disponibile ad altri processi oppure alla stessa applicazione terminata e quindi riavviata successivamente. L’informazione deve essere conservata anche quando l’elaboratore si guasta oppure viene spento. Molto più brevemente possiamo, quindi, concludere dicendo che l’informazione va conservata e deve essere eliminata solo quando l’utente lo fa presente al sistema operativo.
L’informazione, come si sa, rimuove le incertezze all’interlocutore che la consulta. In alcuni casi essa può essere di tipo esclusivo, valida cioè solo per un solo utente. Tuttavia, è assai frequente anche la condivisione dell’informazione: più processi devono avere la possibilità di accedere alle informazioni in maniera concorrente (ecco a cosa serve la multiprogrammazione). La questione dell’informazione, delle sue caratteristiche in termini di spazio occupato, permanenza e condivisione viene gestita da strutture dati detti file. I file memorizzano l’informazione, ne permettono la condivisione e forniscono un adeguato spazio di indirizzamento. Quella parte del sistema operativo che si occupa dei file è detta file system.
Il file system fornisce una struttura dati utile alla gestione dei file, implementandoli e fornendo loro alcune caratteristiche come: il nome del file, il nome del proprietario, estensione, protezione ed alcune operazioni di gestione. Ogni sistema operativo crea nel proprio file system una propria astrazione di file (lo implementa cioè in un certo modo), per questo motivo esistono diversi file system ed ognuno di questi è gestito da un sistema operativo.
La prima caratteristica di un file system che osserveremo è la denominazione dei file, essa permette di rintracciare l’informazione univocamente quando il nome dato ad un file è unico in tutto il sistema di elaborazione. Un processo può creare un file ed assegnare a questo un determinato nome, quindi può iniziare a scriverne le informazioni che esso dovrà contenere. In una successiva esecuzione, lo stesso processo, può così richiamare il file precedentemente creato (adesso il processo conosce il nome del file poichè esso stesso lo ha creato oppure è l’utente che suggerisce al processo un determinato nome) e riprendere la manipolazione dell’informazione. Non esistono regole precise circa i nomi dei file, ogni sistema adottando un proprio file system è vincolato anche dalle regole che questo impone all’intero sistema. Ad ogni modo, tutti i file system di sistemi operativi consentono l’utilizzo di stringhe di caratteri come nome per file. Tali stringhe possono poi essere lunghe da uno ad otto caratteri e di recente sono ammesse anche stringhe lunghe 255 caratteri (in seguito vedremo come ciò si realizza). Alcuni sistemi consentono di inserire nel nome del file anche i caratteri speciali ed i simboli di interpunzione, altri sistemi ammettono invece solo i caratteri dell’alfabeto. I caratteri che compongono un nome possono poi essere riconosciuti nelle due forme di scrittura possibili, quella cioè in minuscolo ed in maiscolo sicchè ci sono sistemi che fanno differenza tra nomi scritti interamente in maiuscolo e/o minuscolo (come i sistemi UNIX che per questo motivo sono anche detti sensitive case) mentre altri sistemi ritengono uguali i nomi scritti nelle due possibili varianti (come ad esempio fanno i sistemi MS-DOS e quelli della famiglia WINDOWS).
Il nome di un file è poi suddiviso in due pezzi o più pezzi, la prima parte dell’intero nome è il vero nome del file mentre le stringhe di caratteri che seguono il punto si riferiscono all’estensione del file. Nei sistemi con file system MS-DOS un nome intero di file è diviso in un nome di file avente lunghezza da uno ad otto caratteri e da una estensione che invece può essere lunga da una a tre caratteri. L’estensione che accompagna il nome del file fornisce al sistema operativo delle interessanti informazioni aggiuntive. Abbiamo detto che un file contiene l’informazione, ma come leggerne o manipolarne il contenuto? Quando l’utente decide di mandare in esecuzione un file esso dapprima lo seleziona e successivamente lo manda in esecuzione premendo il tasto di invio (oppure si può anche dare un doppio click quando il puntatore del mouse punta sul nome del file). A questo punto il sistema operativo consulta una lista di associazione tra estensioni di file e programmi utente che hanno l’abilitazione ad eseguire il file che è stato scelto, quindi manda in esecuzione il programma utente abilitato ed apre il file selezionato. In questo caso l’estensione è servita al sistema operativo per rintracciare il programma utente capace di manipolare l’informazione nel file, questo accade ad esempio nei sistemi MS-DOS e WINDOWS.
Nei sistemi UNIX l’estensione del file può essere più articolata, il file può non avere alcuna estensione oppure può averne una o più. L’estensione è infatti (diversamente dai sistemi MS-DOS e WINDOWS) un informazione aggiuntiva data all’utente (e non al sistema operativo). Pertanto mentre un file nominato appunti.txt nei sistemi MS-DOS è aperto dal programma che detiene la gestione dei file con estensione .txt (ad esempio il programma utente notepad.exe oppure wordpad.exe) nei sistemi UNIX l’estensione .txt suggerisce all’utente il contenuto del file: un file di testo tipicamente codificato in ASCII (sarà l’utente che deciderà, poi, con quale programma utente andarlo ad aprire). Ecco un elenco di alcune estensione ed una loro breve descrzione:
Alcune estensioni |
Descrizione |
.bak |
File di backup |
.c |
File sorgente di un programma scritto in linguaggio C |
.hlp |
File di aiuto, solitamente una guida al programma utente |
.html |
File o documento formattato con tag HTML |
.jpg |
File di immagine codificata con algortimo standard JPG |
.mp3 |
File audio compresso codificato con l’algoritmo MP Ver.3 |
.mpg |
File video codificato con algoritmo standard MPEG |
.o |
File oggetto compilato ma non ancora collegato |
File di documento strutturato secondo il formato PDF |
|
.ps |
File di documento strutturato secondo il formato PS |
.tex |
File di input per il programma TEX di UNIX |
.txt |
File di testo generico codificato in ASCII |
.zip |
File di archivio compresso codificato con l’algoritmo ZIP |
.rar |
File di archivio compresso codificato con l’algoritmo RAR |
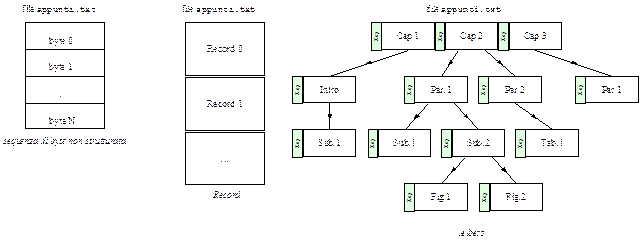
Detto ciò, procediamo nella trattazione dei file occupandoci adesso della struttura dei file. Esistono tre possibili strutture di file:
- sequenza di byte non strutturata: il file è visto dal sistema operativo cone una sequenza di byte. Si tratta dell’implementazione più flessibile dal momento che l’utente può inserire nel file qualunque cosa, qualunque byte. Dall’altra parte, tuttavia, il sistema operativo non fornisce alcun supporto ai file: non impedisce i nomi troppo lunghi ai file, non pretende un estensione, non limita e/o evita il contenuto del file. Nonostante ciò è la struttura di file usata dai sistemi UNIX ed MS-DOS;
- sequenza di record: si tratta dell’evoluzione della precedente implemetazione. Il file è una sequenza di record avente una lunghezza fissa. Ogni record ha poi una propria struttura ed organizzazione interna. Per questo motivo la scrittura, oppure la lettura, del file viene indirizzata indicando un numero di record e la colonna (questo sistema era ad esempio utilizzato nei vecchi sistemi con schede perforate in cui ogni scheda 132 colonne ed ognuna di essa aveva la capacità dicontenere 80 caratteri!);
- struttura ad albero: il file è formato da un albero di record non tutti della stessa lunghezza. Ogni record ha poi un campo chiave e l’albero è ordinato rispetto a tale chiave. A differenza della precedente struttura che accede al file accedendo man mano al record successivo nella struttura ad albero l’accesso è assai più veloce: si accede, infatti, ad una parte del file fornendo un opportuna chiave che identifica il blocco di interesse;
Ogni sistema di calcolo adotta un file system per modellare l’entità file, un sistema operativo può tuttavia comprendere diversi formati e/o tipi di file. Nei sistemi WINDOWS ed UNIX, ad esempio, esistono file regolari, file speciali e directory. I file regolari sono quelli che contengono l’informazione e sono strutturati secondo le volontà del programmatore che decide quindi l’organizzazione dell’informazione. Per ogranizzare e tenere ordinati i file sono poi necessari particolari file, le directory. Esse conservano e mantengono la struttura del file system, tipicamente ad albero, ed organizzano i file in più sottodirectory. In UNIX, inoltre, esistono file speciali che modellano alcune periferiche di input e di output.
L’informazione nei file regolari può essere formattata secondo lo standard ASCII, in tal caso la stampa del file ne riproduce esattamente il contenuto. In alcuni casi, invece, i file regolari sono file di tipo binario. L’informazione è in tal caso mascherata o codificata nel file e solo il programmatore, oppure il programma utente ne conosce la struttura interna e quindi la collocazione. Ad esempio, in un file binario eseguibile di UNIX prendono posto diverse informazioni aggiuntive oltre all’informazione vera e propria. Il file ha più sezioni informative: intestazione, testo, dati, bit di rilocazione e tabella dei simboli. Nell’intestazione del file binario sono suggerite le dimensioni del testo, qualche flag e/o bit protezione e gli indirizzi di partenza nel file di alcuni blocchi informativi.

In un file binario di tipo archivio sono impacchettati tutti i moduli e le procedure compilate e non ancora collegate. Ogni modulo è preceduto da una intestazione (anche questa in forma binaria). Inutile dire che la stampa di un file binario provoca in uscita delle stampe incomprensibili dal momento che l’informazione è codificata.
L’accesso ad un file può avvenire in due modi:
- accesso sequenziale, è la modalità di accesso prevista ad esempio per i nastri magnetici. Prima di accedere ad un record bisogna leggere tutti quelli che lo precedono. Ciò comporta un enorme tempo di attesa e per questo motivo si usa quasi sempre l’altra modalità di accesso;
- accesso casuale, permette di accedere ad un record dell’informazione senza leggere quelli precedenti. Per fare ciò si fornisce ad una istruzione particolare quale è seek l’indirizzo di partenza, in questo modo una successiva operazione di lettura avrà inizio a partire dal suddetto indirizzo;
Ogni sistema prevede per i file una serie di attributi, quelli maggiormenti usati riguardano la data e l’ora di creazione, la dimensione del file, la data e l’ora dell’ultimo accesso al file, alcuni flag per i permessi ed altre informazioni utili al sistema oppure all’utente. Ogni sistema adotta diversi attributi, nella tabella che segue è possibile osservare una lista completa dei possibili attributi di file:
Attributo |
Significato |
Proprietario |
Indica l’utente che ha generato il file |
Dimensione corrente |
Esprime la dimensione in byte del file |
Dimensione massima |
Esprime la massima dimensione in byte |
Protezione |
Decide chi può accedere al file |
Password |
Parola chiave per l’accesso al file |
Flag di lettura |
0=lettura e scrittura 1=sola lettura |
Flag di sistema |
0=file normale 1=file di sistema operativo |
Flag di archivio |
0=file non copiato 1=file con copia |
Flag di file nascosto |
0=file normale 1=non mostrare il file |
Flag di ASCII |
0=file ASCII 1=file binario |
Flag di bloccaggio |
0=file accessibile 1=file bloccato |
Lunghezza di un record |
Indica la dimensione di un record in byte |
Lunghezza di una chiave |
Indica lo spazio occupato da una chiave |
Tempo di creazione |
Data e ora di creazione del file |
Tempo di ultimo accesso |
Data e ora dell’ultimo accesso al file |
Tempo di modifica |
Data e ora dell’ultima modifica al file |
Alcune system call che trattano i file sono già state affrontate nel corso di queste stesse note, per maggiore completezza ne riportiamo di seguito un elenco riassuntivo:
- create: crea un file senza dati, predispone tutte le strutture necessarie al file;
- delete: elimina un file dopo averne indicato il nome;
- open: apre un file in una delle modalità previste, lo scopo della chiamata è la predisposizione in memoria centrale di tutte le strutture dati del file;
- close: in alcuni sistemi esiste un limite massimo al numero dei file che possono essere aperti, questa chiamata di sistema chiude il file e libera in questo modo lo spazio in memoria principale;
- read: legge un certo numero di byte dal file;
- write: scrive i byte nel file sovrascrivendo quelli già presenti nel file;
- append: scrive i byte nel file collocandoli in coda a quelli già presenti nel file;
- get attributes: restituisce gli attributi del file disponendoli in una apposita struttura dati;
- set attributes: modifica un attributo del file;
- rename: cambia il nome ad un file;
La sola esistenza dei file non garantisce l’ordine desiderato dall’utente per la memoria virtuale ma al contrario si limita a contenere i file in unica directory che per questo motivo viene detta directory principale o directory radice. In tal caso non possono esistrere due file con lo stesso nome. Le directory sono particolari file che contengono altri file, in questo modo ogni utente può avere la propria directory ed inserire, pertanto, i propri file. La soluzione con un unica directory è più semplice da realizzare e qualora debba essere cercato un file esisterà una sola directory in cui cercare.
La possibilità di generare altre directory per ordinare i file da luogo a diversi livelli di directory: in ogni directory può essere creata un altra directory che per questo motivo si dirà essere una sottodirectory della directory superiore:
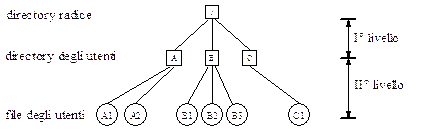
La gerarchia a livelli delle directory elimina i conflitti che possono sorgere sui nomi dei file, ogni utente può tuttavia avere l’esigenza di un ulteriore livello di astrazione per le directory, magari perchè vuole un secondo file con lo stesso nome di uno già esistente. Per questo motivo i moderni sistemi consentono una gerarchia di directory che permette di avere un numero arbitrario di sottodirectory:
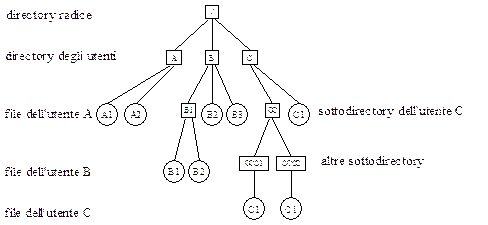
Quando il file system è organizzato su una gerarchia di directory, tipicamente detta ad albero, è necessario una procedura sistematica che permetta di individuare un file. Un primo metodo prevede l’uso del cosiddetto path assoluto: per indicare un file si parte sempre dalla direcotory radice (che per i sistemi UNIX è / mentre per i sistemi MS-DOS è C:\), quindi si elencano tutte le sottodirectory intermedie fino al file (neisistemi MS-DOS il separatore di directory è il simbolo \, nei sistemi UNIX il separatore è il simbolo /). Ad esempio, il path assoluto: /c/cc/ccc1/c1 indica il file c1 della directory ccc1 che è una sottodirectory della directory cc che a sua volta è una sottodirectory della directory c che, per finire, è una sottodirectory della directory radice.
Un altro metodo per indicare un path di file fa uso del concetto di directory di lavoro. Per directory di lavoro si intende l’attuale directory selezionata dall’utente (nei sistemi UNI ad esempio, l’utente si sposta dalla directory radice alla directory bin mediante il comando di change directory cd bin). Dopo aver eseguito il precedente comando la directory di lavoro che prima coincideva con la directory radice è la directory bin. Nei sistemi UNIX il comando pwd restituisce l’attuale directory di lavoro. Se ad esempio ci troviamo nella directory di lavoro CC il pathname relativo /ccc1/c1 indica il file c1 della directory ccc1 che è una sottodirectory della directory di lavoro cc. Alcune system call che hanno a che fare con le directory sono state già trattare nel corso di queste stesse note, tuttavia preferiamo riportare per completezza un elenco riassuntivo delle possibili operazioni su directory:
- create: crea una directory vuota (mkdir per i sistemi UNIX);
- delete: elimina una directory;
- opendir: apre una directory;
- closedir: chiude una directory;
- readdir: legge da un elemento il prossimo elemento, è utile a fare una lista di file;
- rename: cambia il nome ad una directory;
- link: il collegamento permette ad una directory di comparire in altre sottodirectory;
- unlink: rimuove il collegamento;
L’utente, che sicuramente userà i file e le directory, si preoccupa di come i file sono chiamati ed in quale path essi vengono memorizzati. Coloro che invece studiano i file e le directory si preoccupano (almeno dovrebbero farlo), invece, di come questi vengono implementati.
Implementazione di un file system
Il file system può essere visto secondo due punti di vista, quello dell’utente e quello del sistema operativo. L’uente riceve dal file system le astrazioni necessarie per i file e per le directory, a lui spettano le assegnazioni dei nomi per i file e per le directory nonchè la struttura gerarchica per le directory. Il sistema operativo, invece, si prende cura di come implementare in maniera efficiente delle opportune strutture dati, di come deve avvenire la gestione tramite le system call e di come lo spazio sul disco debba essere mantenuto. I file system vengono memorizzati sui dischi, sia essi magnetici oppure ottici come i cd-rom, ogni disco è diviso in partizioni, ed ogni partizione del disco può avere un proprio file system. Il settore 0 di ogni disco è detto master boot record o più brevemente MBR, in esso è contenuto il programma per mandare in esecuzione il sistema operativo. Verso la fine dell’MBR si trovano le tabelle delle partizioni, ogni partizione ha un blocco di avvio ed altri blocchi informativi. Una sola partizione è segnata come attiva per cui quando il sistema viene avviato il BIOS legge ed esegue il programma contenuto nell’MBR che a sua volta individua la partizione attiva ed esegue il blocco di avvio di quest’ultima. Nel blocco di avvio di ogni partizione, solitamente, si trova il loader del sistema operativo. A parte il blocco di avvio che è presente in ogni partizione, la struttura dei blocchi di partizione varia a seconda del file system utilizzato dal sistema.

Per implementare un file in file system sono possibili diverse strategie:
Allocazione contigua
Nell’allocazione contigua lo spazio di indirizzamento dell’intero disco è suddiviso in blocchi e le operazioni di lettura e scrittura interessano uno o più blocchi. Ad ogni file viene assegnato un certo numero di blocchi consecutivi, di questi solo l’ultimo blocco a volte non è interamente riempito (ad esempio perchè il file non è un multiplo esatto della dimensione del blocco di disco). Per la lettura/scrittura è sufficiente conoscere l’indirizzo del blocco iniziale del file. Ad esempio, se un disco è diviso in blocchi da 1Kb allora un file utente di 100Kb sarà allocato in uno spazio contiguo del disco fisso di 100 blocchi. Se la dimensione dei blocchi sul disco è invece di 2Kb occorreranno 50 blocchi contigui. L’implementazione dei file secondo uno schema a blocchi contigui è senza dubbio la più facile dal punto di visto realizzativo: per tenere traccia dei blocchi di un file è sufficiente conoscere l’indirizzo del primo blocco ed il numero di blocchi che lo compongono;la posizione dei successivi file dipende dalla dimensione del singolo blocco e da quanti blocchi lo precedono; la lettura del file può avvenire poi alla massima velocità poichè i blocchi del file sono contigui, pertanto, per leggere un file è necessaria una sola operazione di posizionamento sul blocco iniziale.
Nonostante la semplicità realizzativa la soluzione dei blocchi contigui presenta alcuni inconvenienti abbastanza significativi. Un primo problema, come già anticipato, è il mancato utilizzo dell’ultimo blocco che sarà sempre parzialmente occupato. Meglio quindi non fare i blocchi del disco troppo grandi, si rischia di inutilizzare gran parte dello spazio di un blocco se il file non è esattamente un multiplo della dimensione del blocco. Inoltre, se il sistema è in esecuzione per un certo periodo di tempo, la rimozione di alcuni file rischia di frammentare il disco. In altre parole i buchi dovuti agli spazi liberati dai file adesso non più utili non sempre coincidono con gli spazi necessari ad allocare i nuovi file. Se questi possono essere in alcuni casi accodati all’ultimo blocco del disco non ancora utilizzato prima o poi sarà necessaria una operazione di compattazione, senza dubbio dispendiosa in termini di tempo. Lo spazio ancora inutilizzato potrebbe allora essere organizzato meglio: i buchi liberi ad esempio potrebbero essere ordinati per dimensionare, in tal caso prima di allocare un nuovo file si dovrebbe dapprima conoscere la dimensione finale del file in maniera tale da avviare una ricerca del buco sul disco. Nonostante questa forte limitazione l’allocazione contigua è ancora usata come ad esempio avviene nella scrittura del file system per cd-rom. In questo caso, davvero singolare, è infatti possibile conoscere a priori le dimensioni dei file che si intendono scrivere sul cd-rom, oltre al fatto che le dimensioni dei file, una volta scritte sul cd-rom non cambieranno mai più.
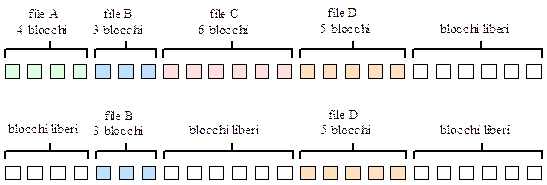
Allocazione con lista concatenata
Nell’allocazione contigua è emerso il problema della frammentazione del disco, così come già fatto per la gestione della memoria principale, è possibile allocare i blocchi del disco secondo una lista concatenta. Ogni blocco ha una parola che viene destinata al puntatore al prossimo blocco, la restante parte del blocco è quindi destinata alla memorizzazione dell’informazione. Così facendo si elimina il problema della frammentazione e si può usare ogni blocco del disco, anche se questo appartiene ad un buco troppo piccolo per l’allocazione contigua. Tuttavia l’allocazione dei blocchi del disco secondo lo schema delle liste concatenate ha alcuni svantaggi:
- se una parola del blocco o comunque una sua frazione è destinata al puntatore al prossimo blocco allora la restante parte da destinare all’informazione non è più una potenza di due. In altre parole lo spazio realmente dedicato all’informazione non coincide con la dimensione del blocco. Si tratta di una complicazione forte per la programmazione dal momento che molti programmi usano leggere e scrivere blocchi di informazione che sono multipli della potenza di due;
- l’eliminazione dei problemi dovuti alla frammentazione è ulteriormente svantaggiosa poichè l’accesso ad un blocco del file, ad esempio l’n-esimo blocco, avviene solo dopo n-1 accessi al file. In altre parole è necessario scorrere l’intera lista dei blocchi prima di arrivare al blocco desiderato (nell’allocazione contigua la lettura richiedeva, invece, la conoscenza dell’indirizzo del primo blocco del file e la lettura poteva quindi avvenire alla massima velocità vista la contiguità dei file);
Allocazione con lista concatenata e tabella in memoria
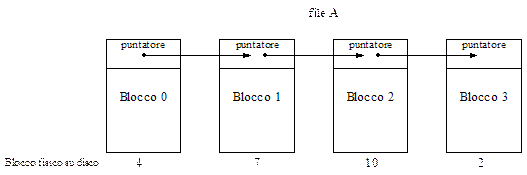
Entambi gli svantaggi analizzati per lo schema di allocazione con lista concatenata possono essere rimossi, la soluzione consiste nel mettere i puntatori di un file al blocco successivo in una tabella. La tabella ha tante righe per quanti sono i blocchi del disco, in corrispondenza di ogni riga (che fa riferimento ad un blocco fisico) si segna il successivo blocco che lo segue. In questo modo è possibile mappare su questa tabella l’allocazione dei blocchi di un file, la terminazione di un file è segnata con un simbolo speciale, ad esempio -1. In questo modo è possibile seguire tutti i blocchi di un file e l’informazione occupa tutto lo spazio messo a disposizione dal blocco. La tabella, poi, risiede in memoria principale, pertanto, le operazioni di scorrimento della lista concatenata fino al blocco di file interessato possono avvenire molto più velocemente. La tabella in memoria è detta file allocation table o più brevemente FAT. Qui lo svantaggio è che la dimensione della tabella è proporzionale alle dimensioni del disco! Se il disco è da 60 GB e se i blocchi sono da 1 KB la FAT avrà 60·220 righe, uno per ogni blocco del disco che dovrà così avere un puntatore al prossimo blocco di log260·220≈4byte. La FAT occuperà per questo motivo almeno 240 MB (4·60·220 byte). Il file A dell’esempio precedente con lista concatenata è stato qui allocato in una FAT per disco da 16KB con blocchi da 1KB, il file A inizia a partire dal blocco 4 del disco:
0 |
Blocco non usato |
1 |
Blocco non usato |
2 |
-1 |
3 |
Blocco non usato |
4 |
7 |
5 |
Blocco non usato |
6 |
Blocco non usato |
7 |
10 |
8 |
Blocco non usato |
9 |
Blocco non usato |
10 |
2 |
11 |
Blocco non usato |
12 |
Blocco non usato |
13 |
Blocco non usato |
14 |
Blocco non usato |
15 |
Blocco non usato |
Il blocco 2 del disco non punta a nessun blocco successivo, ed essendo la terminazione del file A è quindi contrassegnato con il simbolo -1.
Allocazione con i-node
L’allocazione dei file basata su i-node permette di tenere traccia dei blocchi appartenenti ad un file associando al file una piccola struttura dati che è appunto l’i-node (index node, nodo indice). L’i-node è una piccola tabella o array in cui scrivere i blocchi di disco associati al file e gli attributi che lo caratterizzano. Siccome il file potrebbe crescere oltre il limite previsto dall’array (oppure potrebbe già impegnare un numero di blocchi del disco il cui elenco è tale da superare i posti a disposizione nell’array) si decide di associare alcune delle celle dell’array ad indirizzi di blocchi del disco che contengono altre di queste strutture dati. L’i-node è assai più vantaggioso dell’allocazione con tabella FAT poichè la struttura dati adoperata è molto più snella (si tratta di un array con un fissato numero di celle), innanzittutto l’array non è proporzionale alle dimensioni del disco come invece è la FAT. Altra cosa vantaggiosa è che l’i-node deve essere caricato in memoria solo quando il file corrispondente viene aperto, la FAT invece deve trovarsi costantemente in memoria.
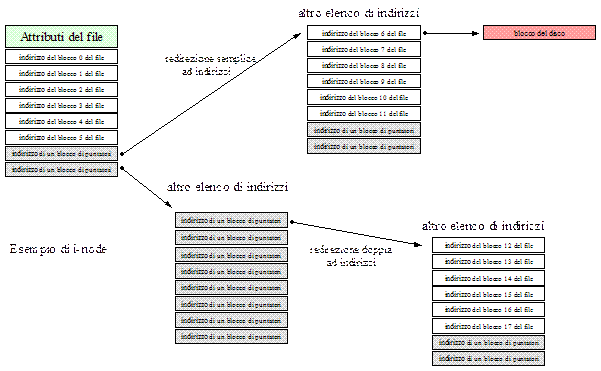
Per implementare una directory in un file system sono possibili due diverse strategie, entrambe si differenziano per come vengono gestiti gli attributi e come avviene la gestione dei nomi lunghi. La directory è il contenitore per i file, quando un file deve essere aperto il sistema operativo lo rintraccia tramite il path di directory che conducono ad esso (se il file è modellato come una collezione contigua di blocchi) oppure cercando il numero di i-node (se il file è modellato con i-node). Gli attributi del file possono essere memorizzati direttamente nella directory che quindi prevede una struttura di elementi aventi una lunghezza fissata per contenerli (nome, dimensione e date), tale approccio è ad esempio seguito nei file system basati su FAT. Nei sistemi che invece usano file system basati su i-node viene seguita una diversa possibilità, gli attributi sono memorizzati nell’i-node, così facendo l’elemento di directory è assai più snello poichè contiene solo il nome del file nella directory ed il suo i-node.
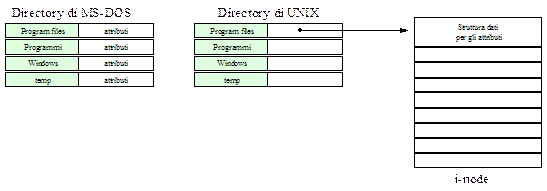
Le directory sono dunque viste come dei normali file. Nei sistemi con FAT esse sono viste come degli “entry point” verso i blocchi iniziali dei file in essa contenuta, ricordiamo infatti che la tabella contiene il nome del file, gli attributi e la locazione del primo blocco. Per i sistemi basati su i-node le directory contengono gli indirizzi dei blocchi con gli i-node dei file contenuti.
Altra questione da trattare è quella che riguarda i nomi lunghi nei sistemi MS-DOS i file hanno una lunghezza che varia da 1 a 8 caratteri ed una estensione opzionale da 1 a 3 caratteri, mentre nei sistemi UNIX Ver.7 sono supportati nomi da 1 a 14 caratteri, incluse le estensioni. Tuttavia è ben nota la possibilità di memorizzare nome più lunghi come attualmente fanno i moderni calcolatori. Una possibile soluzione consiste nel fissare una lunghezza massima per i nomi, ad esempio 255 caratteri, ed usare uno dei due schemi, quelli con FAT oppure i-node.
Se decido di assegnare un certo spazio (ad esempio un certo numero di campi dati di n byte per ogni file, in base alla lunghezza del nome del file saranno necessari un certo numero del suddetto campo dati) nella directory per memorizzare i nomi lunghi dei file posso tuttavia sprecarlo inutilmente se questi poi non lo impegnano effettivamente. Oltretutto, poi, se decido di rimuovere un file rimarrà un buco in tale struttura pari al numero di elementi di lunghezza fissa ad esso assegnato che non sempre coincide con il numero di elementi richiesti dal nuovo file.
Una diversa soluzione è invece quella che prevede la scrittura dei nomi dei file in unico heap della directory: ogni elemento che fa riferimento ad un file inizia con un puntatore all’heap della directory verso il nome del file rappresentato. In questo caso la directory occupa lo spazio che effettivamente richiede e la rimozione di un file provoca l’aggiornamento dei puntatori (operazione che tra l’altro avviene velocemente dal momento che l’elemento di directory è caricato in memoria).

In tutte le configurazioni descritte fino a questo momento, le ricerche di un nome di file avvengono in modo lineare dall’inizio alla fine della directory; per directory estremamente lunghe la ricerca lineare può essere molto lenta. Un modo per velocizzarla è quella di usare una tabella hash all’interno di ogni directory; se la lunghezza della tabela è n, per inserire il nome di un file, si deve calcolare partendo da tale nome un valore da 0 ad n-1. Ad esempio dividendolo per n e prendendo il resto, oppure sommando le parole che compongono il nome e dividendo la quantità risultante per n, oppure qualche oprazione simile. In ogni caso si ispeziona la componente della tabella corrispondente al codice calcolato, se tale componente è libera, si aggiunge un puntatore all’elemento del file in questione, così gli elementi dei file seguono la tabella di hash per rintracciarlo. Se la componente è già in uso, si crea una lista collegata, la cui testa è raggiungiubile dalla tabella, composta da tutti gli elementi che corrispondono allo stesso valore di hash.
Da quanto finora detto appaiono evidenti le due possibili strategie per la gestione dello spazio di un disco. I file possono essere memorizzati in blocchi contigui, oppure possono essere divisi in un numero di blocchi non necessariamente contigui. Un compromesso simile si era presentato nella gestione della memoria e trovava le soluzioni nella memoria paginata o nella frammentazione. Una sostanziale differenza risiede nel fatto che memorizzando i file in maniera contigua si presenta il problema di spostare il file qualora esso cresca in dimensioni, nella segmentazione ciò non costituiva un grosso problema poiché la memoria principale è assai più veloce del disco, ragion per cui l’operazione di spostamento dei file avviene con molta più velocità. In base a quanto detto la maggior parte dei file system suddivide i file in blocchi di dimensione fissa che non necessariamente sono tra loro contigui. Una scelta assai importante nella progettazione di un file system è la dimensione del blocco di allocazione. Bisogna trovare il giusto compromesso tra l’overhead dovuto alla frammentazione interna (che richiederebbe blocchi più piccoli) e velocità di trasferimento dei dati che invece richiede blocchi grandi. Infatti, i blocchi piccoli hanno il vantaggio di generare una frammentazione che meglio si adatta alla memorizzazione dei file poiché generalmente solo l’ultimo blocco sarà parzialmente occupato, tuttavia avere un blocco piccolo implica anche una tabella FAT più grande (ricordiamo che la tabella FAT ha tante righe per quanti sono i blocchi del disco). Al contrario invece, un blocco dalle dimensioni grandi permette di recuperare l’informazione nel blocco con poche operazioni di lettura ma produce più spazio sprecato. Le operazioni di lettura/scrittura di un disco sono caratterizzate da un tempo di rotazione (medio poichè varia con la distanza periferica del blocco dal centro del disco) e da un tempo di ricerca del blocco. Ad esempio, se un disco di 20 GB ha una traccia di 131072 byte, un tempo di rotazione di 8.33 ms ed un tempo di ricerca di 10 ms, il tempo necessario a leggere un blocco di K byte è:
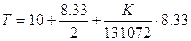
Per blocchi da 1 KB il tempo è di 14.23 ms, per blocchi da 4 KB il tempo è di 14.42 ms e così via...
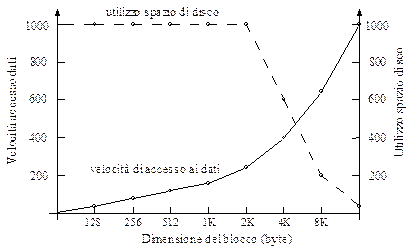
La velocità di accesso al file cresce all’aumentare delle dimensioni del blocco (si leggono/scrivono più informazioni in un colpo solo). Se il file è però troppo grande la velocità di accesso è fortemente condizionata dal tempo di trasferimento (ci vuole più tempo per reperire l’intero file ed il tempo di trasferimento fa abbassare la velocità di accesso). I blocchi piccoli, invece, vanno bene per un buon utilizzo dello spazio del disco. Per questo motivo ogni file system deve arrivare a scegliere un compromesso per la dimensione dei blocchi del disco, tale valore si attesta in un intorno dei 2 KB (come diverse statistiche confermano).
Per tenere traccia dei blocchi liberi si usano due metodi: la lista concatenata dei blocchi liberi e la tecnica della mappa dei bit liberi (come per la memoria principale). Nella lista concatenata ogni blocco contiene una lista di blocchi del disco che sono liberi. Se la dimensione del blocco è di 1024 byte e se per indirizzare ogni blocco occorrono 32 bit (ci sono cioè 232 blocchi sul disco), in ogni blocco ci possono essere 256 numeri di blocchi liberi (ecco il calcolo: 1024·8=8192 sono i bit in un blocco; l’indirizzamento ad un blocco libero avviene con 32 bit, in un blocco sono contenuti 8192/32=256 indirizzi di blocchi liberi). La mappa dei bit occupa meno spazio della lista poiché usa 1 bit per blocco contro i 32 bit della lista (32 bit sono i bit usati dalla lista concatenata per indicare in ogni blocco gli indirizzi di altri blocchi liberi). Un blocco libero è segnato nella mappa di bit con il simbolo 1, un blocco già allocato è segnato, invece, com il simbolo 0. Un disco di 20 GB ha 20·220 blocchi da 1 KB ed una mappa di bit di altrettanti 20·220 bit ed occuperà, quindi, 20·220/8·210=2560 blocchi da 1 KB (2.5 MB). Tuttavia nel caso in cui il disco sia quasi pieno allora la mappa dei bit sarà quasi completa e richiederà più spazio della lista concatenata.
Se viene scelto il metodo della lista concatenata solo un pezzo della lista sarà portato in memoria principale (in tal caso il sistema operativo disporrà di 256 indirizzi di blocchi liberi), quando un file viene creato si accede a tale blocco per reperire gli indirizzi dei blocchi liberi da assegnare. Quando il suddetto blocco di indirizzi si esaurisce si provvede a leggerne un altro dal disco.
Un inconveniente per la bit-map è che essa va tenuta interamente in memoria. Affinché un utente non usi tutto lo spazio del disco si usa assegnare a ciascun utente una quota sul disco, i sistemi operativi con molti utenti offrono questo meccanismo ed introducono due limiti di superamento, uno detto hard (rigido) e l’altro detto soft (variabile). Si concede all’utente la possibilità di superare il limite soft a patto che alla fine della sessione l’utente rientra nella quota a lui assegnata. Il limite hard è invece invalicabile. Nel tenere traccia dei blocchi liberi si cerca prevenire l’esaurimento della lista dei blocchi liberi anticipando il caricamento in meoria di un ulteriore lista.
Affidabilità di un file system
Quante copie avete dei vostri file? La perdita dei file e quindi dell’informazione che essi trasportano non è quasi sempre rimediabile e comporta oltretutto un eccessivo tempo di recovery dell’hard disk. A differenza di qualunque altro componente di un sistema, la cui sostituzione può avvenire nel giro di qualche ora rivolgendosi ad un rivenditore, la sostituzione di un hard disk ormai danneggiato se pur possibile non farà contento l’utente che avrà in mente la lista di tutti i file persi. L’inaffidabilità di un file system può essere prevenuta con le copie di backup dei file. Se il danno per un utente privato che perde i propri file è già di per se una catastrofe, figuriamoci allora quanto lo sia per le aziende. Per questo motivo, chi lavora intensamente con un sistema di calcolo e produce grosse quantità di informazione si affida a sistemi di backup dei dati, tipicamente orientati a nastri magnetici. Il backup dei file può avvenire anche una volta al giorno se l’azienda lo ritiene necessario. I motivi che possono indurre al backup possono essere ricondotti a due tipologie di eventi: la prima di queste è senza dubbio dovuta ai disastri ambientali circostanti all’elaboratore (incendi, inondazioni, frane... tutte cose che per fortuna non capitano spesso) che, data la rarità degli eventi, non inducono seriamente l’utente a intraprendere una programmazione di backup dei file; l’altra tipologia di eventi è invece riconducibile alle disattenzioni dell’utente che magari cancella per sbaglio un file utile. Quest’ultimo problema è così frequente che in WINDOWS, quando un file viene rimosso esso non viene affatto cancellato, ma viene spostato in una directory particolare, il cestino, da cui è possibile riprendere il file e ripristinarlo nel path che occupava prima della cancellazione.
Se poi ogni volta occorre fare il backup dell’intero sistema allora il tempo da spendere per questa operazione è davvero tanto, meglio quindi non effettuare il backup dei file che sono rimasti immutati dall’ultima operazione di backup. Se non altro questo accorcia la durata dell’operazione di backup. Backup di questo tipo si dicono anche dump incrementali. La strategia da seguire è la seguente: ogni settimana si esegue un dump completo dell’intero file system del sistema ed ogni giorno, invece, si esegue un dump incrementale dell’ultimo backup. Se da un lato ciò riduce di molto i tempi di backup (a patto che non molti file vengono modificati tra un giorno ed un altro) l’operazione di ripristino dei dati, qualora sia necessaria, deve seguire tutti i precedenti backup: a partire dal backup completo si aggiornano su di esso tutti i file modificati e contenuti nel backup incrementale che lo segue cronologicamente parlando.
La possibilità di compattare i file di backup è senza dubbio un interessante fonte di attrazione per l’utente che in questo modo potrebbe pensare di risparmiare (oppure far risparmiare alla sua azienda) diversi supporti per backup. Tale possibilità va comunque presa con molta prudenza poichè un eventuale errore sul supporto di backup, che ci può sempre stare, può compromettere la comprensione dell’intero file e non consentire la ricostruzione dei file di backup (l’algoritmo di compattazione usato per i file potrebbe non ricostruire ogni singolo file). In caso di errore sul supporto di backup, senza alcuno algoritmo per la compattazione dei dati, non sarà possibile ricostruire il solo file che sfortunatamente è capitato proprio su quel pezzo di nastro, ad ogni modo meglio quest’ultima ipotesi che la precedente.
Un altra area in cui l’affidabilità di un file system si confronta con altri file system è la coerenza del file system. Molti file system leggono blocchi, li modificano e in un secondo momento li scrivono; se il sistema ha un crash prima che tutti i blocchi modificati siano stati scritti, il file system può trovarsi in uno stato inconsistente. Questo è un problema critico specialmente se alcuni dei blocchi che non sono stati scritti sono blocchi di i-node (avete mai provate a spegnere un sistema UNIX prima che il sistema operativo venga caricato?), blocchi directory o blocchi contenenti la lista dei blocchi liberi! La maggior parte dei sistemi operativi si affida a servizi noti come scandisk (nei sistemi WINDOWS) e fsck (nei sistemi UNIX). Questi programmi vengono attivati dopo un crash del sistema e controllano la coerenza del file system. Per effettuare il controllo della coeranza sui file del file system il sistema operativo si costruisce due liste: nella prima lista verranno segnate le presenze dei blocchi in uso, nella seconda lista i blocchi liberi. Un file consistente avrà un bit di presenza per i blocchi in una o nell’altra lista. Oltre caso, banale, di consistenza appena descritto sono possibili altre tre combinazioni:
- blocco mancante: il blocco del file analizzato non compare nella lista dei blocchi del file (non vi appartiene) e nella lista dei blocchi liberi. Esso occupa solo spazio e per questo motivo il blocco viene aggiunto alla lista dei blocchi liberi;
- bloccoduplicato nella lista libera: nella lista dei blocchi liberi il contatore delle presenze per un blocco ha più di una presenza. La lista dei blocchi liberi viene ricostruita aggiornando il precedente valore ad 1;
- blocco dati duplicato: di tutti i possibili casi è quello più serio. La cosa peggiore che può succedere è che lo stesso blocco dati sia presente in due o più file. Se uno di questi due file fosse rimosso il blocco doppiamente presente sarebbe messo nella lista libera, portando a una situazione in cui lo stesso blocco è contemporaneamente usato e libero, chiaramente inconsistente. Se entrambi i file sono rimossi il blocco sarà messo nella lista libera due volte. L’azione di recuper che il controllore del file system deve eseguire è quella di allocare un blocco libero, copiarvi il contenutodel blocco e inserire la copia in uno dei file; in questo modo non si modifica il contenuto dell’informazione dei file sebbene uno dei due file è inconsistente. L’errore dovrebbe essere segnalato all’utente per permetterne la scelta.
Il file system ISO9660
Come abbiamo precedentemente anticipato lo standard per cd-rom in termini di file system è il file system ISO 9660 che si basa sull’allocazione contigua dei blocchi di file e di directory. Ogni cd-rom che è presente sul mercato osserva il suddetto standard che garantisce quindi la compatibilità e l’interleggibilità per ogni sistema. La differenza sostanziale da un cd-rom con un disco magnetico sta nell’organizzazione interna. Siccome il disco magnetico si affida all’assegnazione dei blocchi per file che non necessariamente deve essere contigua la sua organizzazione interna è basata su una struttura a cilindri concentrici suddivisi in settori che a loro volta sono suddivisi in tracce di K blocchi. I cd-rom, invece, hanno una spirale contigua di blocchi da 2352 byte, il carico informativo effettivo è comunque di 2048 byte (2 KB). Alcuni byte del blocco, infatti, sono destinati a strutture dati informative. La dimensione tipica dei cd-rom in commercio è di 700 MB. In 700 MB è possibile contare 700·220/2352=312077 blocchi di dati. Tali blocchi possono descrivere un contenuto interamente digitale se usati in ambito informatico e quindi come supporti dati per elaboratori. Oppure, possono descrivere un contenuto interamente analogico del supporto che in questo modo sarà utilizzato per contenuti di tipo audio. Occorrono 75 blocchi per riprodurre 1 solo secondo di audio, pertanto, avendo a disposizione 312077 blocchi è possibile riprodurre da cd-rom 312077/75=4161 secondi che corrispondo a circa 70 minuti di audio (provate a ripetere i calcoli con supporti cd-rom da 800 MB, scoprirete che in tal caso si potranno riprodurre 80 minuti di audio).
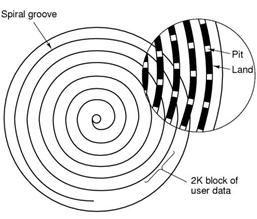
Il file system ISO 9660 supporta la gestione di 216-1 cd in un insieme di file system spezzato su più cd-rom. Ognuno di essi può poi essere partizionato in più volumi logici di dimensioni più piccole. I primi 16 blocchi della spirale di blocchi contigui non sono usati dallo standard che li lascia quindi liberi per i produttori che in questo modo hanno, ad esempio, la possibilità di impegnarli collocando qui un eseguibile per mandare in esecuzione automatica un programma da cd-rom quando quest’ultimo è inserito nel lettore. Sono poi possibili altri usi dei suddetti primi 16 blocchi.
Dopo i primi 16 blocchi inutilizzati troviamo un descrittore primario con informazioni di carattere generale sul cd-rom, in esso si trovano svariati campi dati informativi come: l’identificatore di sistema (da 32 byte); l’identificatore di volume (da 32 byte); l’identificatore del distributore (da 128 byte) e l’identificatore del preparatore dei dati (da 128 byte); Sempre nel descrittore primario si raccolgono altre importanti informazioni come la dimensione dei blocchi logici (di solito 2048 byte ma anche le successive potenze di 2 sono ammesse, 4096 e 8192 byte ad esempio); data di creazione e data di scadenza del cd-rom ed un elemento di directory principale o directory radice che indicherà in quale blocco del cd-rom essa sia stata collocata. Dalla suddetta locazione è poi possibile localizzare il resto del file system. Il produttore e/o chi prepara i dati riempe questi dati con stringhe di sole lettere maiuscole ed alcuni caratteri di tipo numerico. Un elemento di directory sicompone dei diversi campi dati:
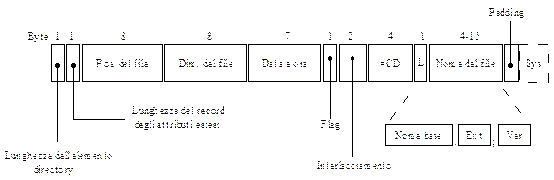
Ogni elemento di directory è di dimensione variabile (solitamente si compone di 10/12 campi dati), l’ultimo è marcato con un bit particolare. Gli stessi campi dati, per dare la possibilità a tutti i sistemi di leggerli, sono poi codificati sia in ASCII che in binario. Ad esempio, un numero di 16 bit userà 4 byte (2 byte in ASCII e altri 2 byte in binario).
Il primo campo dati indica la dimensione in byte dell’elemento directory, questo essendo di 1 byte (8 bit) ne limita la dimensione nell’intervallo da 0 a 255 byte. Lo stesso discorso si ripete per la descrizione della lunghezza dei record per attributi estesi. Se i files non fanno uso degli attributi estesi questo campo dati non è necessario (per questo motivo dicevamo prima che il numero di campi dati che compone un elemento di directory è variabile). Il successivo campo dati nell’elemento di directory sta ad indicare la posizione del file sul cd-rom, in altre parole ne indica il blocco iniziale (con 8 byte (64 bit) è possibile indirizzare 264-1 blocchi di cd-rom. Anche se ci possono sembrare tanti ricordiamo che in un cd-rom esistono 312077 blocchi e che il file system può essere spezzatto su un numero più di un cd-rom).
Il campo dati relativo alla data e l’ora in cui il cd-rom è stato scritto è di 7 byte, il formato usato per la data è del tipo AAAA-MM-GG mentre per l’ora hh-mm-ss. Nel campo flag si celano diversi bit tra cui quello per indicare al sistema la possibilità di marcare un elemento come non visibile e, quindi, di nasconderlo quando vengono generate le liste di files.
Per l’interlacciamento dei pezzi di file che risultano spezzati su pù cd-rom sono usati 2 byte. Il campo dati successivo di 4 byte (32 bit) indicia il numero di cd-rom che quindi varia tra 232-1. Il campo dati L indica la lunghezza in byte (quindi compresa tra 0 e 28-1 byte) del successivo campo dati, quello cioè relativo al nome del file. Quest’ultimo a sua volta si suddivide in un campo dati per il nome, un campo dati per l’eventuale estenzione ed un campo dati per specificare la versione del file (in binario). Il campo dati padding serve, invece, allo stuffing dell’elemento di directory che deve sempre essere un numero pari di byte (ciò favorisce ad esempio un controllo di parità su tutti i byte letti). Infine, l’ultimo campo dati system use (non sempre presente assieme al padding) o più brevemente sys non è specificato dallo standard che lo assegna per usi di sistema. I sistemi UNIX ad esempio usano il suddetto campo per imlementare le cosiddette estensioni Rock Ridge, tali estensioni permettono di rappresentare su cd-rom il file system di UNIX. Le estensioni Rock Ridge prevedono, dunque, nel campo dati system use i seguenti campi: PX per attributi POSIX; PN per numerare i dispositivi (in UNIX ogni dispositivo è modellato con un file); SL per rappresentare i link simbolici che in UNIX usano una variabile di conteggio per stabilire se il file è usato oppure no; NM per i nomi alternativi che in UNIX sono di sicuro più lunghi e articolati su più estensioni; CL per indicare la posizione del figlio in termini di i-node; PL per indicare la posizione del genitore in termini di i-node;RF per specificare la rilocazione di una directory all’interno della gerarchia e aggirare così una forte limitazione al file system ISO 9660 che limita ad 8 directory il massimo livello di profondità nella gerarchia ad albero del file system.; TF per contenere i tre campi dati timestamp solitamente inclusi negli i-node di UNIX.
Anche la comunità di utenti che usava i prodotti Microsoft ha dopo poco avanzato le proprie estensioni per il file systema ISO 9660, le estensioni Joiliet. Tali estensioni permettono: l’utilizzo di nomi lunghi per i file e per le directory; l’utilizzo di un set di carattere Unicode per i nomi di file (utile alla rappresentazione dei nomi per quei paesi che non usano l’; una profondità di struttura delle directory superiore agli otto livelli previsti; l’utilizzo di directory con estensioni.
Il file system di MS-DOS
Il file system di MS-DOS è molto simile, per certi versi ne è l’estensione, al file system di CP/M. La prima versione di MS-DOS (MS-DOS Ver.1.0) era limitata ad una sola directory proprio come faceva CP/M. MS-DOS, inoltre, funziona solo con piattaforme INTEL e non supporta la multiprogrammazione. A partire da MS-DOS Ver.2.0 è stata aggiunta la possibilità di avere un file system gerarchico con una profondità di directory arbitraria. La lettura da un file, mediante apposita system call che genericamente indichiamo come open, permette di ottenere un handle (gestore) per il file da manipolare. Nella chiamata di sistema viene specificato il path (sia relativo oppure assoluto) che è analizzato in ogni sua componente fino ad accedere al file (se questo esiste).
Le directory in MS-DOS usano elementi di directory di 32 byte che possono tuttavia avere dimensioni variabili, in esso si trovano informazioni come: il nome del file, gli attributi del file, informazioni di tipo timestamp per le date, il blocco di inizio file e la dimensione espressa in byte del file. Nel campo attributi (8 bit) si trovano alcuni flag nuovi come quello relativo all’archiviazione (indica se il file è stato già archiviato con una copia di backup, anche se non è usato dallo stesso file system permette alle applicazioni utente di gestire questa possibilità), quello relativo alla proprietà di file nascosto (un file nascosto non compare nelle liste dei file quando queste vengono generate per mezzo dell’apposito comando dir), quello relativo alla proprietà di file di sistema (un file di sistema non può essere cancellato se l’utente prova a chiamare su di esso il comando del).
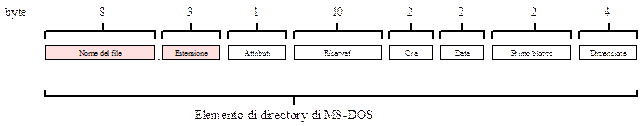
Il nome di file prevede una lunghezza di otto caratteri più una estensione variabile da uno a tre caratteri. Per il campo dati relativo all’ora si utilizzano 2 byte (16 bit), è pertanto possibile rappresentare 216-1=65535 valori distinti contro gli 86400 secondi contenuti in 24 ore. Per questo motivo la precisione per il campo dati relativo ai secondi è stata ridotta a ± 2 secondi (ogni bit per il campo dati relativo ai secondi vale 2 secondi). I 2 byte (16 bit) del campo dati riservati alla rappresentazione dell’ora sono così suddivisi:
- 5 bit per i secondi permettono di rappresentare 25=32 elementi contro i possibili 60 secondi contenuti in un minuto solare. Quindi, si è scelto di usare 1 bit ogni 2 secondi;
- 6 bit per i minuti permettono di rappresentare 26=64 elementi contro i possibili 60 minuti contenuti in un ora solare;
- 5 bit per le ore permettono di rappresentare 25=32 elementi contro le possibili 24 ore contenute in un giorno solare;
Anche il campo relativo alla rappresentazione di una data (2 byte=16 bit) è stato suddiviso:
- 5 bit per il giorno permettono di rappresentare 25=32 elementi contro i possibili 31 giorni contenuti in un mese solare del calendario;
- 4 bit per il mese permettono di rappresentare 24=16 elementi contro i possibili 12 mesi contenuti in un anno solare;
- 7 bit per l’anno permettono di rappresentare 27=128 elementi, l’anno base è il 1980. Per questo motivo il massimo anno rappresentabile è il 1980+128=2108;
Per la dimensione in byte del file si usano 4 byte (32 bit), questo significa che un file può essere grande da 0 a 232=4GB. Tuttavia la dimensione massima è stata comunque limitata a 2 GB. Il file system MS-DOS usa la tabella FAT, per questo motivo nell’elemento di directory sono destinati 2 byte (16 bit) per esprimere la posizione del primo blocco. Questo significa che si possono specificare al massimo 216-1 blocchi (65535 blocchi) che nelle versioni FAT-12 (che usa 12 bit per l’indirizzamento su disco del blocco) usa blocchi che possono essere grandi almeno 512 byte. I blocchi sono qui chiamati cluster.
Per FAT-12 con blocchi da 512 byte è possibile gestire una partizione di 212·512=2 MB (con 212=4096 voci nella tabella FAT, una per ogni blocco del disco), si tratta di un file system attualmente buono solo per floppy disk.
Con l’avvento degli hard disk il problema della dimensione della partizione limitata ad un certo valore è stato risolto aumentando la dimensione fisica dei blocchi sul disco che possono essere anche di 1, 2 e 4 KB. Così facendo FAT-12 riusciva a gestire al massimo una partizione da 212·4096=16 MB. Gli hard disk più grandi di 16 MB erano partizionati in più unità logiche che MS-DOS nomina con le lettere dell’alafabeto maiuscole (D:\ E:\ F:\ etc...). MS-DOS era in grado di gestire 4 partizioni, pertanto l’hard disk più grande gestibile da MS-DOS era da 64 MB (suddiviso in 4 partizioni da 16 MB).
Per gli hard disk più grandi si pensò ad una nuova versione, FAT-16 (16 bit per l’indirizzamento ai blocchi sul disco). La FAT adesso aveva 216=65535 voci, una per ogni blocco del disco. Per FAT-16 le dimensioni dei blocchi potevano essere di 2, 4, 8, 16 e 32 KB. La massima partizione gestibile poteva essere grande 216·32K=2 GB. Il massimo numero di partizioni contemporaneamente gestibili da MS-DOS era ancora 4, per questo motivo l’hard disk più grande che MS-DOS poteva gestire con FAT-16 era di 8 GB (suddiviso in 4 partzioni da 2 GB).
Con il sistema operativo WINDOWS 95 è stato fatto debuttare il nuovo file systema, FAT-32 (che in verità usa 28 bit per l’indirizzamento dei blocchi sul disco piuttosto che 32 bit come la sigla lascia intendere). In questo modo la massima partizione gestibile da MS-DOS potrebbe essere di 228·32K=8TB (i blocchi possono ancora essere di 4, 8, 16 e 32 KB), essa è stata tuttavia limitata a 2 TB (2048 GB) in quanto internamente il sistema tiene traccia della dimensione della partizione in settori da 512 byte usando numeri da 32 bit, pertanto 512·232 da al massimo 2 TB.
Dimensione blocco |
FAT-12 |
FAT-16 |
FAT-32 |
512 byte |
2 MB |
/ |
/ |
1 KB |
4 MB |
/ |
/ |
2 KB |
8 MB |
128 MB |
/ |
4 KB |
16 MB |
256 MB |
1 TB |
8 KB |
/ |
512 MB |
2 TB |
16 KB |
/ |
1024 MB |
2 TB |
32 KB |
/ |
2048 MB |
2 TB |
Con FAT-2 è allora possibile decidere quale dimensione si preferisce per il blocco fisico. L’amministratore di sistema può in questo modo optare per blocchi più piccoli se i files sull’elaboratore hanno in media una piccola dimensione, in questo modo si limita lo spazio sprecato a causa della frammentazione dell’ultimo blocco allocato.
Il file system di Windows 98
A partire da WINDOWS 98 è stato permesso all’utente l’uso di nomi di file più lunghi dei soliti 8 caratteri che MS-DOS metteva a disposizione. WINDOWS 98 utilizza un file system basato su FAT-32 che quindi permette l’uso dei moderni hard disk ormai sufficientemente capienti. La possibilità di dare ai files nomi lunghi è senza dubbio la caratteristica più importante del file system di WINDOWS 98. Microsoft poteva implementare una tale pensando a nuovi elementi di directory, più lunghi di quelli di MS-DOS e quindi anche più adeguati al suddetto problema. Nonostante ciò non è stata questa la strada percorsa da Microsoft che avendo ancora diversi utenti legati alle precedenti versioni di WINDOWS (come ad esempio WINDOWS Ver.3.1 e WINDOWS 95) ha cercato di mantenere la compatibilità all’indietro con i rispettivi file system e quindi con MS-DOS.
Se dunque la compatibilità all’indietro con le vecchie versioni doveva essere garantita di sicuro il nuovo file system dovrà avere una struttura comune ai vecchi elementi di directory di MS-DOS. La soluzione adottata da Microsoft sfrutta i 10 byte non usati nell’elemento di directory di MS-DOS, ciò favorisce l’aggiunta di altri campi dati.
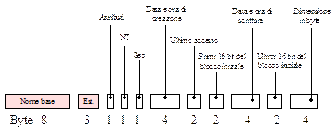
Il campo dati NT (1 byte) è stato aggiunto per favorire la compatibilità anche verso WINDOWS NT in termini di visualizzazione dei nomi di file con lettere maiuscole e minuscole. Il campo dati Sec aumenta la risoluzione della data che con 16 bit non poteva essere efficiente (Ricordate il problema dei secondi? In MS-DOS 1 bit valeva 2 secondi!). Nei 10 byte prima riservati e adesso utilizzati dal file system si trovano anche 4 byte per la data e l’ora di creazione del file; 2 byte per memorizzare l’ultimo accesso (Non l’ora! Solo la data di ultimo accesso!); 2 byte per memorizzare i primi 16 bit del blocco iniziale. Ed i nomi lunghi? Come vengono implementati?
La soluzione adottata da Microsoft consiste nell’associare ad ogni file due nomi, un nome è compatibile con le regole imposte dal vecchio file system, quello di MS-DOS, l’altro nome è invece leggibile per sistemi che adottano il sistema operativo WINDOWS 98. Quando l’utente crea un file assegnando per questo un nome, il sistema operativo verifica dapprima se il nome scelto dall’utente è compatibile con i nomi ammessi da MS-DOS. A tale proposito il sistema operativo si accerta che la lunghezza non superi gli 8 caratteri ammissibili e che il nome sia interamente scritto in maiuscolo. Un nome siffatto è sia compatibile con il vecchio MS-DOSche con WINDOWS 98. Tuttavia, se il nome pernsato dall’utente non risponde ai due requisiti appena citati il sistema operativo si attiva affinchè venga ricavato un secondo nome per il file (il primo nome, quello lungo, è leggibile da WINDOWS 98 ed è ammesso dal file system. A partire da questo si genera il secondo nome, quello per MS-DOS) leggibile anche da MS-DOS. L’algoritmo usato è il seguente: il sistema operativo prende i primi sei caratteri del nome lungo scritto dall’utente e li trasforma in caratteri maiuscoli; quindi aggiunge a questi sei caratteri i simboli ~1. Se il file così generato già esiste il sistema operativo fa seguire ai primi sei caratteri il simbolo ~2 (invece che ~1) e così vià... I caratteri spazi inseriti nel nome sono cancellati nella versione MS-DOS del nome mentre alcuni caratteri speciali sono tradotti con il simbolo di underscore. Detto ciò, un file avente nome appunti di sistemi operativi.txt, per essere compatibile con i sistemi MS-DOS, è memorizzato nella sua forma estesa (secondo nome) e nella forma ridotta APPUNT~1.txt (primo nome). Il nome lungo è comunque memorizzato in più elementi di directory, ogni elemento può contenere 13 caratteri (gli elementi di directory contenenti i vari pezzi del nome sono memorizzati in ordine inverso e sono preceduti da un numero di sequenza. All’ultimo numero di sequenza si aggiunge 64). Gli elementi di directory che seguono il primo utilizzano il campo dati Sec (quello relativo ai secondi che è per loro ridondante) per effettuare una checksum (per un controllo di parità) su 8 bit.
L’esigenza di un campo dati per il controllo di parità è presto spiegato: è cosa ormai ben nota quella di poter avviare un sistema in entrambe le modalità, quella cioè relativa al sistema operativo WINDOWS 98 e quella invece relativa alla modalità MS-DOS. Se, dunque, in modalità MS-DOS si decidesse di rimuovere un file verrebbe cancellato solamente il primo elemento di directory lasciando ancora sul disco quelli relativi al nome lungo del file (MS-DOS è infatti inconsapevole dell’esistenza degli altri elementi di directory). Gli stessi elementi di directory, poi, potrebbero essere assegnati ad un nuovo file appena creato e verrebbero ad assumere un valore inconsistente nei confronti del nuovo nome del file. Il campo dati per il controllo della parità permette al sistema operativo di scovare questi difetti e di correggerli scrivendo in essi i caratteri associati al vero nome del file (notare qui, che in tal caso il nuovo file creato sotto MS-DOS avrebbe al massimo una lunghezza di 8 caratteri, tale nome coinciderà anche con quello usato da WINDOWS 98).

Il file system di Windows NT
NTFS è il file system nativo di WINDOWS NT e supporta, inoltre, i formati FAT e HPFS (HPFS è il file system di IBM per OS/2) per fornire delle possibili forme di migrazione dagli altri sistemi operativi (sebbene Microsoft non incluse il supporto per HPFS in NT Ver.4.0).
L’obiettivo per cui Microsoft decise di implementare NTFS era quello di superare le limitazioni degli altri due file system, compatibili con NT, e di fornire caratteristiche avanzate che un sistema operativo a livello aziendale richiede. Per esempio, NTFS supporta un sistema di sicurezza a livello di file e directory molto granulare, mentre FAT e HPFS non hanno caratteristiche di sicurezza. In aggiunta, lo schema di allocazione di NTFS può indirizzare efficacemente dischi rigidi di notevoli dimensioni. FAT e HPFS sono invece entrambi limitati dalla dimensione dei dischi. Infine, dei tre file system, NTFS è l’unico che supporta la codifica Unicode per gli ambiti internazionali ed ha caratteristiche per prevenire la corruzione di file e del file system in caso di guasto.
Alla fine degli anni ’80 Microsoft progettò NTFS parallelamente allo sviluppo iniziale di Windows NT. Quando l’infrastruttura di base di NTFS fu realizzata e verificata la sua funzionalità, Microsoft diede come direttiva al team che stava sviluppando NT di usare NTFS come file system. Dato che NTFS doveva essere un nuovo file system, progettato da zero, il suo progetto poteva incorporare caratteristiche che potevano superare le limitazioni poste dall’hardware e dai file system dei PC attuali (allo sviluppo di NTFS) e anticipare le richieste degli utilizzatori aziendali del sistema. La cosa più ovvia fu quella di fornire un adeguato supporto ai dischi rigidi che aumentano costantemente le loro dimensioni. Tutti i file system WINDOWS dividono le partizioni dei dischi in unità logiche dette clusters. Il file system FAT usa 16 bit (nella versione classica) per indirizzare clusters, così può indirizzare al più 216 o 65536 cluster diversi. I cluster possono variare in dimensione a seconda della dimensione del disco, ma cluster molto grandi possono portare come risultato a un problema di frammentazione interna oppure parecchio spazio sprecato all’interno del cluster stesso. Per esempio, se un file ha solamente 250 Bytes di dati, esso richiede un intero cluster di spazio allocato su disco il che risulta che più di 15 KB di spazio vanno sprecati in caso di cluster di 16 Kb. Con solo 65536 cluster indirizzabili, un disco FAT con 1KB di spazio per cluster potrebbe indirizzare al massimo un disco di 64 MB. Un disco di 4 GB, per esempio, richiederebbe quindi una dimensione di 64 KB per cluster con i relativi svantaggi che abbiamo visto prima per cluster di così grandi dimensioni. Un disco NTFS invece indirizza i cluster con un indirizzamento a 64 bit. Così anche con 512 Bytes per cluster NTFS non dovrebbe aver difficoltà ad indirizzare dischi con dimensioni che probabilmente non vedremo ancora per anni.
Gli sviluppatori di FAT e HPFS non considerarono il fatto della sicurezza all’interno del file system mentre NTFS usa lo stesso modello di sicurezza di WINDOWS NT. Discretionary access control lists (DACLs) e system access control lists (SACLs), controllano chi può fare operazioni sui file e quando un evento deve essere loggato, le operazioni sono registrate nel formato nativo di WINDOWS NT all’interno del file system NTFS. Il file system FAT usa i caratteri ASCII a 8 bit per nominare i file e le directory. Impiegando quindi set di caratteri ASCII mettiamo una limitazione ai nomi usabili con FAT che equivalgono a quelli inglesi (in generale simbolici). WINDOWS NT ed il file system NTFS usano entrambi il set di caratteri a 16 bit Unicode per i nomi. Questa caratteristica di NTFS permette agli utilizzatori di WINDOWS NT sparsi per il mondo di organizzare i loro file usando la loro lingua madre. Infine FAT non prevede nulla per la salvaguardia dei file e del file system in caso di guasti. Se un sistema va in crash quando stiamo creando, aggiornando file e/o directory la struttura FAT sul disco può diventare inconsistente (si puossono verificare uno dei precedenti casi trattati). La situazione può consistere in una perdita delle informazioni modificate oppure in una totale corruzione del disco e conseguente perdita di parecchie informazioni residenti sul disco. Questo rischio è inaccettabile per il mercato a cui WINDOWS NT è rivolto. Il file system NTFS ha quindi integrato un sistema di logging di transazioni in modo tale che quando una modifica deve essere implementata, NTFS si fa una nota della modifica da fare in un file speciale di log. Se il sistema va in crash, NTFS può esaminare il file di log e usarlo per ripristinare ad uno stato consistente il sistema con il minimo possibile di dati persi.
I vari tool per la formattazione (inizializzazione) dei dischi in NTFS fanno una stima automatica della dimensione delle unità d’allocazione in funzione della dimensione del disco. Queste stime possono anche essere modificate manualmente dall’amministratore del sistema. Le stime fatte direttamente prendono in considerazione il discorso dello spazio sprecato, frammentazione interna e quindi prestazioni generali e cercano di ottimizzarle tutte con un compromesso.
Le informazioni associate alla gestione del disco sono registrate all’interno del disco come file speciali. I dati registrati all’interno di questi file e tutte le informazioni inerenti all’NTFS all’interno dei file utente e delle directory vengono detti metadata (alcuni file di tipo metadata iniziano con il simbolo $). Quando si inizializza un disco con file system NTFS, esso inserisce al suo interno 11 metadata files. Questi file sono generalmente invisibili quando esploriamo un volume NTFS con i tool classici come ad esempio Explorer oppure Firefox.
In aggiunta al sistema di log per evitare perdite di dati sui volumi NTFS, il file system NTFS protegge i suoi dati su disco con un sistema di firme. Quando in una lettura capita un errore, NTFS identifica il cluster come danneggiato e quindi procede alla rilocazione dei dati presenti su quel cluster e poi all’aggiornamento del metadata file $BADCLUS in modo tale da evitare di riutilizzare lo stesso cluster in futuro. Il metadata file $BITMAP, invece, è un grande array di bit in cui ogni bit corrisponde a un cluster sul disco. Se il bit è off allora il cluster risulta libero altrimenti, è in uso. Questo file è mantenuto per tener traccia dei cluster liberi su disco per l’allocazione di nuovo spazio. Il cuore del file system NTFS è la MFT (master file table). Essa è analoga alla file allocation table nel file system FAT perché MFT mappa tutti i file e le directory sul disco, inclusi i metadata files dell’NTFS stesso. La MFT è divisa in unità discrete chiamate records. In uno o più record, NTFS registra i metadati che descrivono un file o le caratteristiche di una direcory (informazioni sulla sicurezza e altri attributi come file a sola lettura oppure file nascosto) e la loro locazione sul disco. Sorprendentemente la stessa MFT è un file che NTFS mappa usando dei record all’interno della MFT stessa. Questa struttura lascia la possibilità alla MFT di espandersi oppure di restringersi.
I file e le directory sono identificati all’interno della MFT usando i relativi record che descrivono quindi l’inizio dei loro metadati all’interno della MFT stessa. I record sono solitamente di 1KB (come ad esempioavviene per WINDOWS NT 4.0) ma possono essere anche più grandi. Ecco un esempio della MFT:

Il file $MFTMIRR è un file di complemento, in caso di disastri al file system, per la prevenzione di perdita di dati. Esso contiene la copia dei primi 16 record della MFT. NTFS lo registra a metà del disco circa mentre la MFT è all’inizio dello stesso. Se il file system NTFS ha un problema nella lettura della MFT allora esso si riferisce ad un suo duplicato. La locazione della MFT e della sua copia sono registrate nel boot record del disco (un file da 512 bytes posto all’inizio del disco stesso).
L’accesso ai dati della MFT incide sulle performance di un disco con NTFS, così NTFS cerca delle soluzioni per accedere alla MFT in modo più rapido possibile. Dato che la MFT è un file residente su volume NTFS esso può ingrandirsi e rimpicciolirsi ed anche frammentarsi. Questa frammentazione si verifica perché NTFS non può allocare in anticipo lo spazio che la MFT occuperà. Quando la MFT cresce e qualche altro file sta occupando anche lo spazio che è a ridosso della parte finale della MFT allora NTFS inizia a guardare altrove sul disco per avere dello spazio libero.
L’accesso più veloce si realizza quando vengono fatte delle operazioni sul disco in maniera sequenziale ma in una MFT frammentata ciò non può avvenire ed NTFS ha allora bisogno di più letture per accedere. Questo può portare ad un abbassamento delle performance. Per evitare quanto appena detto il file system NTFS crea una regione di cluster in introno della fine della MFT dove file e directory non possono essere memorizzati. In questo modo si dà la possibilità alla MFT di crescere e/o ridursi senza troppe difficoltà. Infatti, quando lo spazio libero sul disco comincia a scarseggiare, NTFS rilascia un pò dello spazio precedentemente detto. Questo però comporterà per la MFT un rischio di frammentazione in un disco che peraltro è già al limite delle sue capacità (bisogna poi che NTFS non lascia deframmentare a tool esterni la MFT).
La MFT si compone di svariati record, questi contengono alcune informazioni di base che riguardano il record stesso ed espresse sottoforma di header più altri attributi associati invece al file ed alle directory. L’header nel record comprende ad esempio: un numero di sequenza (usati da NTFS per effettuare il controllo di integrità su alcuni campi dati), un puntatore al primo attributo all’interno del record, un puntatore al primo byte libero all’interno del record, il numero di record che appartengono al file etc... NTFS usa gli attributi per immagazzinare tutte le informazioni sui file e le directory. Sul disco gli attributi sono divisi in due componenti logiche: un header ed una parte dati. Nell’header è specificato il tipo di attributo, il nome del file, eventuali flag nonchè la locazione del disco in cui recuperare i pezzi di informazione. Per ottimizzare le prestazioni NTFS registra la parte dati dell’attributo all’interno del record della MFT (quando ciò è possibile) anzichè leggerlo di volta in volta dal cluster. Quando un attributo ha la sua parte dati memoriazzta nella MFT si dice che l’attributo è residente (in caso contrario non residente). Se la parte dati di un attributo è residente nella MFT l’header dell’attributo punta alla posizione dei dati all’interno del record della MFT. Per quanto riguarda gli attributi, invece, NTFS ne prevede 14 tipi diversi.
NTFS Attribute types
Attribute type |
Description |
$VOLUME_VERSION |
Volume version |
$VOLUME_NAME |
Disk’s volume name |
$VOLUME_INFORMATION |
NTFS version and dirty flag |
$FILE_NAME |
File or directory name |
$STANDARD_INFORMATION |
File timestamps and hidden, system and read-only flags |
$SECURITY_DESCRIPTOR |
Security information |
$DATA |
File data |
$INDEX_ROOT |
Directory content |
$INDEX_ALLOCATION |
Directory content |
$BITMAP |
Directory content mapping |
$ATTRIBUTE_LIST |
Describes non resident attribute headers |
$SYMBOLIC_LINK |
Unused |
$EA_INFORMATION |
OS/2 compatibility extended attributes |
$EA |
OS/2 compatibility extended attributes |
Il nome del file, l’attributo per la specifica di attributo residente nella MFT e gli attributi per la sicurezza sono sempre residenti nella record. Le informazioni del record che individuano i pezzi contigui di file si dicono run information (descrivono una sequenza di cluster) e come altre informazioni NTFS hanno dapprima un header che li specifica (l’header indica quale cluster della parte dati dell’attributo è mappata nella run information). Ogni run information indica un blocco iniziale e la durata in blocchi della run information.
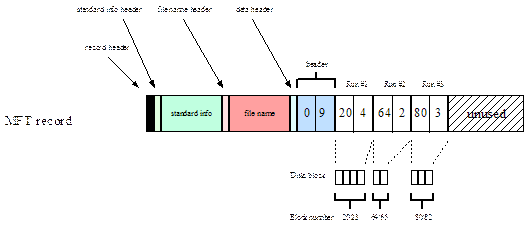
Nella figura è rappresentato un record MFT di un file avente 3 sequenze di run e 9 blochi. Se un file ha troppi attributi che non sono possono essere registrati in un singolo record della MFT, NTFS allora record addizionali e registra la lista degli attributi nel record base. La lista degli attributi punta alla locazione degli attributi nei record addizionali e consiste di un valore per ogni attributo.
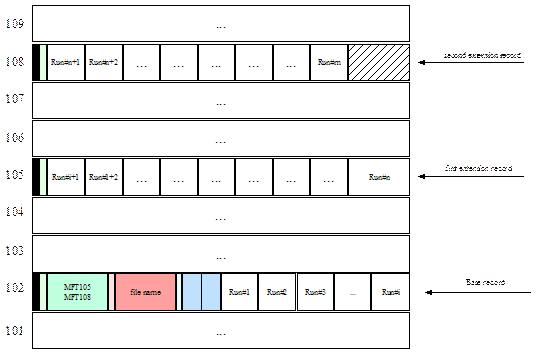
Una directory per NTFS è un attributo indice. NTFS usa gli attributi indice per collocare i nomi dei file. Una directory contiene il nome del file ed una copia delle informazioni dell’attributo standard del file (informazioni sulle date e ore). Questo approccio fornisce una spinta sul piano delle prestazioni quando si naviga all’interno delle directory in quanto NTFS non deve accedere alla MFT per trovare le informazioni da visualizzare per ogni file all’interno della directory.
Quando queste informazioni possono essere contenute interamente in un record della MFT, un tipo di attributo, l’index root, descrive la locazione dei valori nel record. Quando una directory cresce, le informazioni necessarie a descriverla possono superare il record della MFT assegnato. In questo caso, NTFS alloca un index buffers per memorizzare informazioni addizionali. L’header dell’attributo indice specifica la locazione di un buffer. Nell’NTFS di WINDOWS NT Ver.4.0 la dimensione di questo buffer era di 4 KB e le informazioni sulla directory all’interno del buffer erano di lunghezza variabile visto che conteneva nomi di file. Per rendere più efficienti possibili le operazioni sulle directory, NTFS preordina le directory della radice e dei buffer.

Dato che file e directory (inclusi i file di metadati NTFS) cambiano, NTFS scrive delle informazioni nei file log del volume. Il programma chkdsk usa questi file di log per rendere le strutture dati NTFS consistenti e per minimizzare la perdita di dati in caso di crash. I file di log possono essere di due tipi: redo ed undo. Redo memorizza le informazioni riguardanti modifiche che devono essere rifatte in caso di guasto al sistema e i dati modificati non sono sul disco. NTFS usa poi una operazione undo (leggendo cosa ripristinare dall’altro file log, quello undo) per fare un rollback delle modifiche fatte che non erano state completate quando il sistema è andato in crash. Se NTFS sta aggiungendo dati ad un file ed il sistema crash tra il tempo in cui NTFS estendeva la lunghezza del file e il tempo in cui scriveva i nuovi dati, il file di log undo dice ad NTFS di accorciare la lunghezza del file alla sua dimensione originaria durante il recupero.
Il file system di UNIX Ver.7
La versione del file system UNIX che tratteremo è la Ver.7 detta anche fast file system ed è la stessa di quella usata precedentemente per spiegare il file system di UNIX basato su strutture dati i-node. FFS limita la lunghezza dei nomi per file ad un massimo di 14 caratteri e dedica un elemento di directory per ogni file o directory occupando 14 byte per il nome e 2 byte per il numero di i-node. La directory è quindi un array regolare di i-node e nomi di file. Con 2 byte nell’elemento directory il massimo numero di file indirizzabile in una directory è di 216=65535 (64K). Il file system è a forma di albero (capovolto) che con l’aggiunta dei link può essere un grafo aciclico.
La struttura dati più importante di FFS è l’i-node. Esso contiene un certo numero di attributi come la dimensione del file, i tre campi per le date di creazione, ultimo accesso e ultima modifica, il proprietario del file, i relativi permessi ed il contatore per segnare i link che puntano alla directory oppure al file.La struttura dell’i-node è quella già vista, una lista dei primi 10 indirizzi di disco (soluzione buona per i file piccoli) con l’aggiunta di alcuni indirizzi di i-node che puntano ad altri blocchi del file (indirizzamento singolo indiretto, indirizzamento doppio diretto ed indirizzamento triplo indiretto). Quando un file viene aperto il file system deve prendere il nome di file fornito e localozzare i suoi blocchi di disco, ad esempio:
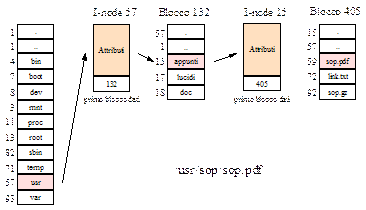
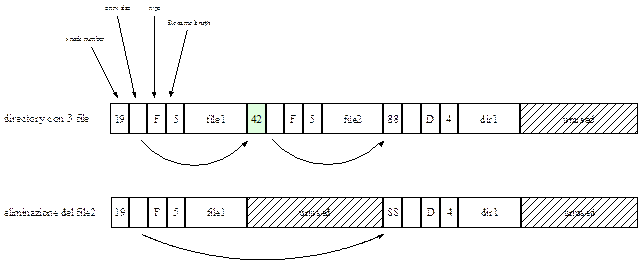
fonte: http://digidownload.libero.it/luca.petrosino/appunti/sop.zip
Autore del testo: non indicato nel documento di origine
File system
Visita la nostra pagina principale
File system
Termini d' uso e privacy